Hadoop en mode cluster¶
Virtualisation avec Docker¶
Utiliser plusieurs machines virtuelles requiert plus des ressources. Pour cela, nous allons utiliser des containers Docker.
Le scénario consiste à déployer 4 nœuds hadoop à partir d'une image Docker fournie ici. Cette image est similaire à celle utilisée avec VirtualBox : elle contient la verion 3.2.1 de hadoop, mrjob, python3 et jupyter.
Déploiement avec Docker¶
 Charger l'image docker à partir du Docker Hub :
Charger l'image docker à partir du Docker Hub :
docker pull hhmida/hadoop:3.2.1
 Créer un réseau virtuel :
Créer un réseau virtuel :
docker network create hadoopnet
 Exécuter 4 instance de l'image avec les noms nodemaster node2, node3, et node4
Exécuter 4 instance de l'image avec les noms nodemaster node2, node3, et node4
docker run -d --network hadoopnet --name nodemaster -h nodemaster -p 8088:8088 -p 9870:9870 -p 9864:9864 -p 19888:19888 -p 8042:8042 -p 8888:8888 hhmida/hadoop:3.2.1
docker run -d --network hadoopnet --name node2 -h node2 hhmida/hadoop:3.2.1
docker run -d --network hadoopnet --name node3 -h node3 hhmida/hadoop:3.2.1
docker run -d --network hadoopnet --name node4 -h node4 hhmida/hadoop:3.2.1
 Formater le nodemaster :
Formater le nodemaster :
docker exec -u hadoop -it nodemaster hadoop/bin/hdfs namenode -format
Démarrage du cluster¶
Démarrer les containers
docker start nodemaster node2 node3 node4
Démarrer les services hadoop
Exécuter ces 2 commandes pour démarrer les services à partir du nodemaster :
docker exec -u hadoop -d nodemaster /home/hadoop/hadoop/sbin/start-dfs.sh
docker exec -u hadoop -d nodemaster /home/hadoop/hadoop/sbin/start-yarn.sh
créer le dossier racine sur HDFS
docker exec -u hadoop -it nodemaster /home/hadoop/hadoop/bin/hadoop fs -mkdir -p .
Démarrer jupyter
Créer un fichier jupyter_notebook_config.py contenant :
c.NotebookApp.allow_origin = '*'
c.NotebookApp.ip = '0.0.0.0'
c.NotebookApp.notebook_dir = '/home/hadoop'
c.NotebookApp.open_browser = False
c.NotebookApp.password = ''
c.NotebookApp.port = 8888
c.NotebookApp.token = ''
docker cp -u hadoop jupyter_notebook_config.py nodemaster:/home/hadoop/.jupyter/
docker exec -u hadoop -d nodemaster jupyter notebook
Arrêt des nœuds¶
docker stop nodemaster node2 node3 node4
Redémarrage du cluster
Pour redémarrer le cluster exécuter les étapes de la section Démarrage du cluster.
Vérification de l'état du cluster¶
Avec la commande jps:
Au niveau du nodemaster

Au niveau de node2 et node3

Accéder aux URLs suivantes pour vérifier l'état et la configuration du cluster
- Cluster Hadoop : http://localhost:8088
- HDFS : http://localhost:9870
- Jupyter notebook : http://localhost:8888
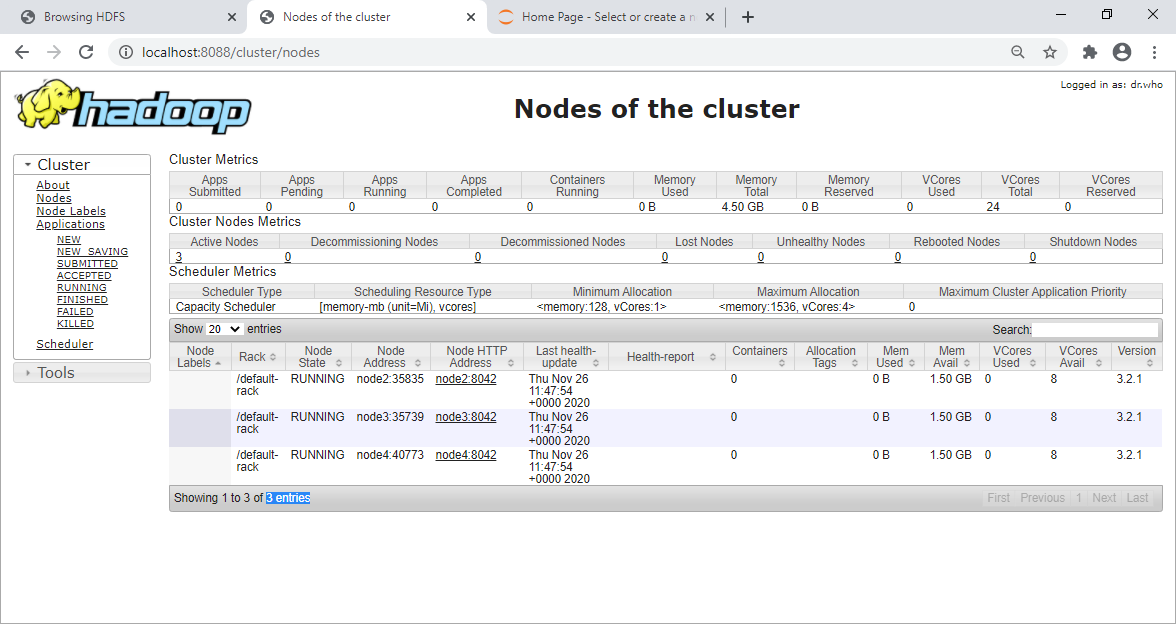
L'interface du Resource Manager montre les n&339;uds :
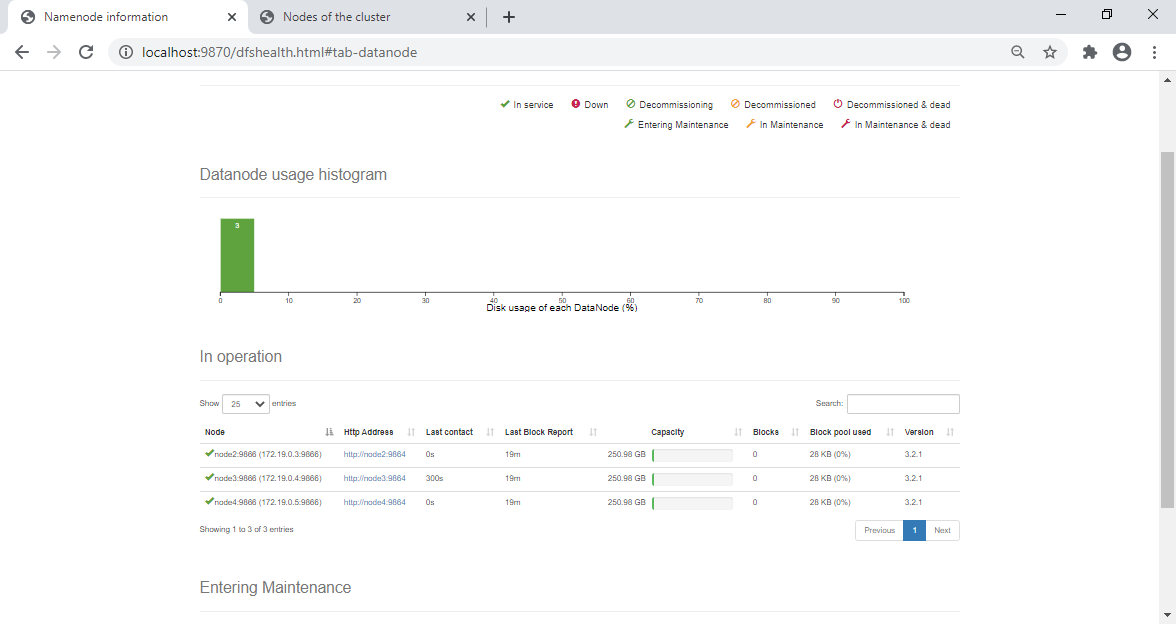
L'interface HDFS montre les nœuds DataNodes actifs :
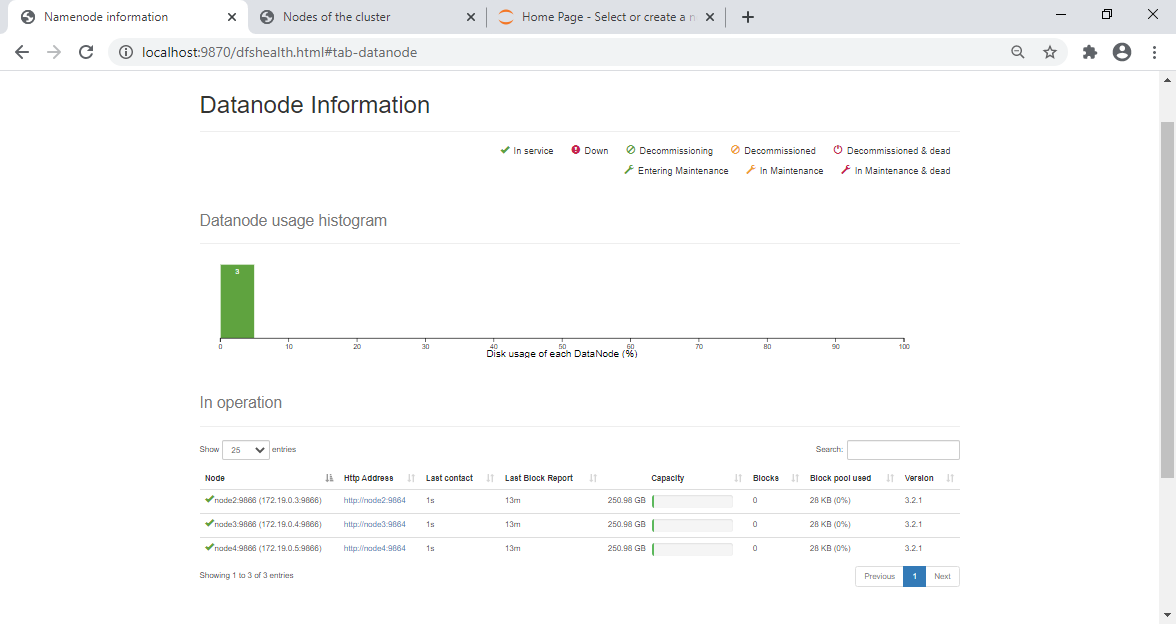
Remarquer la colonne Last contact qui reflète le dernier heartbeaz reçu (inférieur au timeout par défaut : 3 Secondes).
Maintenant, arrêter le nœud node3 :
docker stop node4
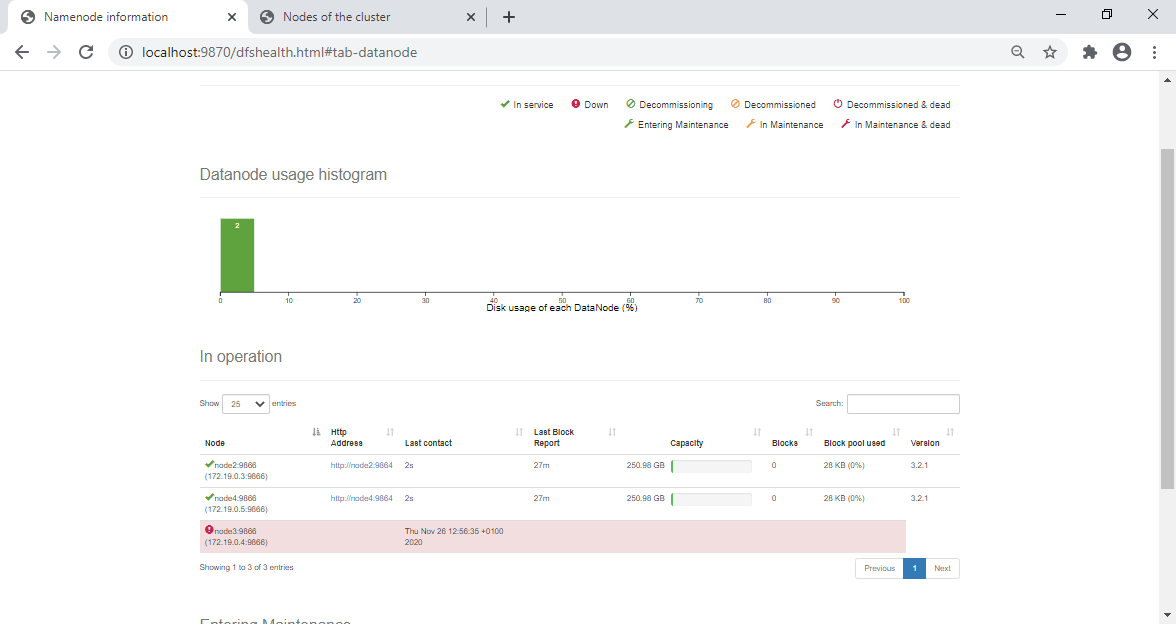
Après 1000 Secondes le nœud est considéré comme indisponible :
Virtualisation avec machines virtuelles¶
Créer un cluster avec la machine virtuelle est plus simple mais nécessite plus de ressources. En effet, dans notre exemple et pour créer un cluster composé d'un maître et 2 workers, vous devez disposer de 8GO de RAM au minimum dont 6GO pour les machines virtuelles.
Modifications sur la machine virtuelle originale¶
Changer le nom de la machine dans le fichier /etc/hostname en nodemaster
sudo echo "nodemaster" > /etc/hostname
Modifier le fichier /etc/hosts :
sudo nano /etc/hosts
Puis écrire les lignes suivantes et enregistrer :
192.168.100.10 nodemaster
192.168.100.20 node2
192.168.100.30 mode3
Modifier les fichiers de configuration de Hadoop
Modifier le fichier /ur/local/hadoop/etc/hadoop/core-site.xml ainsi :
<property>
<name>fs.defaultFS</name>
<value>hdfs://nodemaster:9000</value>
</property>
Changer la replication dans /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
Ajouter cette propriété dans /usr/local/hadoop/etc/hadoop/yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>nodemaster</value>
</property>
Le fichier /usr/local/hadoop/etc/hadoop/workers contient les noms des machines du cluster, il sera utilisé pour démarrer les services depuis le nœud maître.
nodemaster
node2
node3
Workers
nodemaster dans cette configuration est considéré comme namenode et datanode à la fois.
Clonage de la machine virtuelle¶
Créer 2 clones de la machine virtuelle originale qui vont être respectivement node2 et node3.
Chager leurs noms dans /etc/hostname respectivement en node2 et node3
Sur la machine node2 :
sudo echo "node2" > /etc/hostname
Sur la machine node3 :
sudo echo "node3" > /etc/hostname
Changer les adresses IP en 192.168.100.20 et 192.168.100.30 en suivant les étapes suivantes (refaire les mêmes étapes pour node3) :
sudo nano /etc/netplan/00-installer-config.yaml
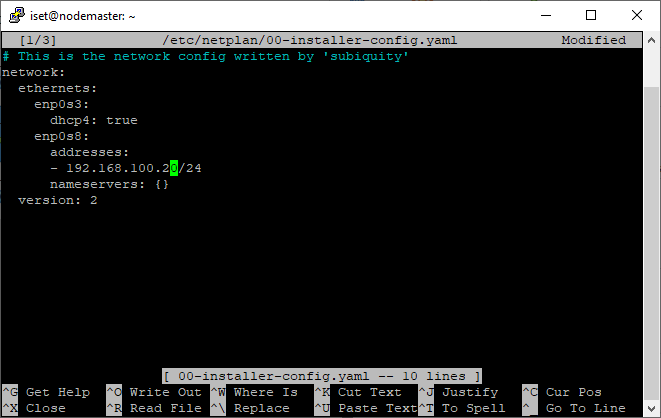
Puis appliquer les modifications :
sudo netplan apply
 Redémarrer les 3 machines et démarrer les services depuis le nodemaster :
Redémarrer les 3 machines et démarrer les services depuis le nodemaster :
start-dfs.sh
start-yarn.sh
Vérifier avec jps ou les URLs http://192.168.100.10:9870 et http://192.168.100.10:8088
Test de l'arrêt d'un nœud : Voir la section pour l'exemple réalisé avec les containers Docker (ici).
Test de Map Reduce sur le cluster¶
Refaire l'exemple wordcout (voir ici):
Mettre le fichier shakespeare.txt sur HDFS :
hadoop fs -put shakespeare.txt
Lancer Jupyter
jupyter notebook --ip=0.0.0.0 --port=8888 --notebook-dir='/home/hadoop' --NotebookApp.token='' --NotebookApp.password=''
Se connecter à http://192.168.100.10:8888, créer le notebook et ajouter le code de l'exemple wordcount :
Pendant l'exécution, vous pouvez visualiser l'état des ressources allouées en cliquant sur Scheduler sur http://192.168.100.10:8088
Après l'exécution réussie sur le cluster, cliquer sur Applications pour vérifier l'état de l'application.
Pour afficher le détail des tâches, il est possible de voir le Job History. Démarrer le serveur job History et accéder à son interface web.
Démarrer le serveur
mapred jobhistoryserver start
Accès à l'interface web : http://192.168.100.10:19888
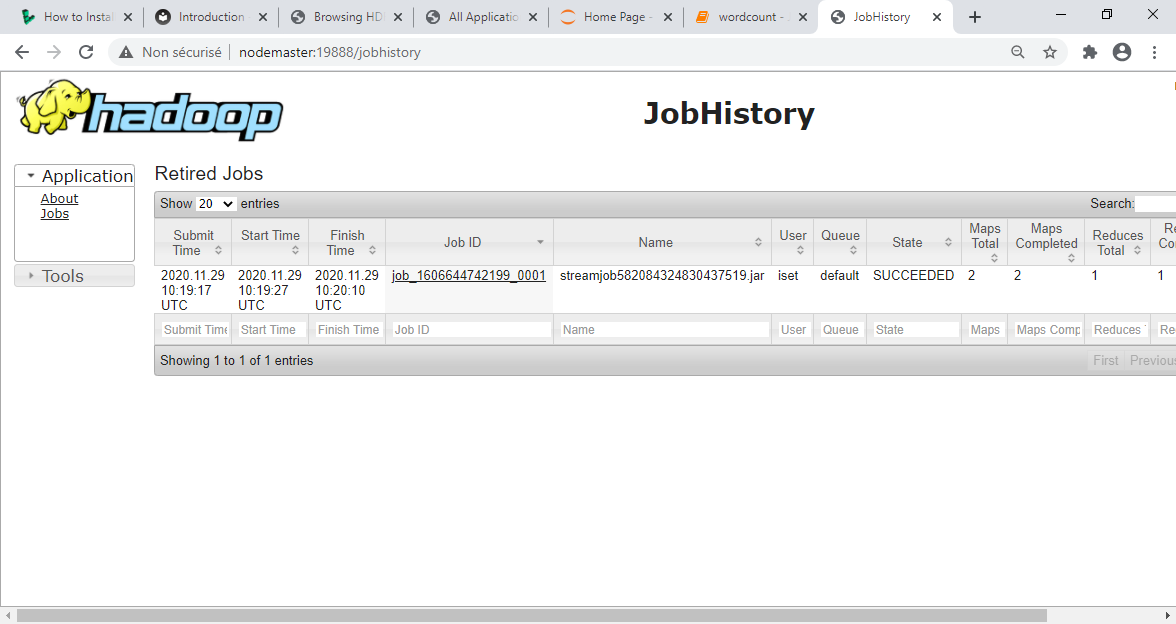
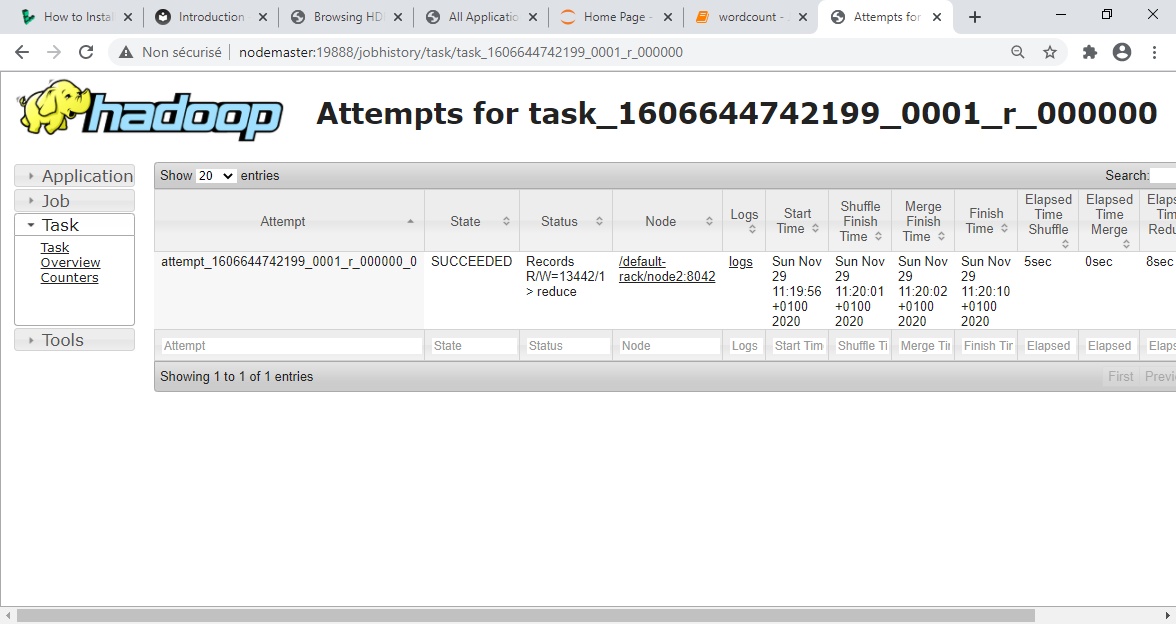
En cliquant sur le Job ID, le nombre de tâches Map et Reduce est affiché (dans ce cas 2 Maps et 1 Reduce) 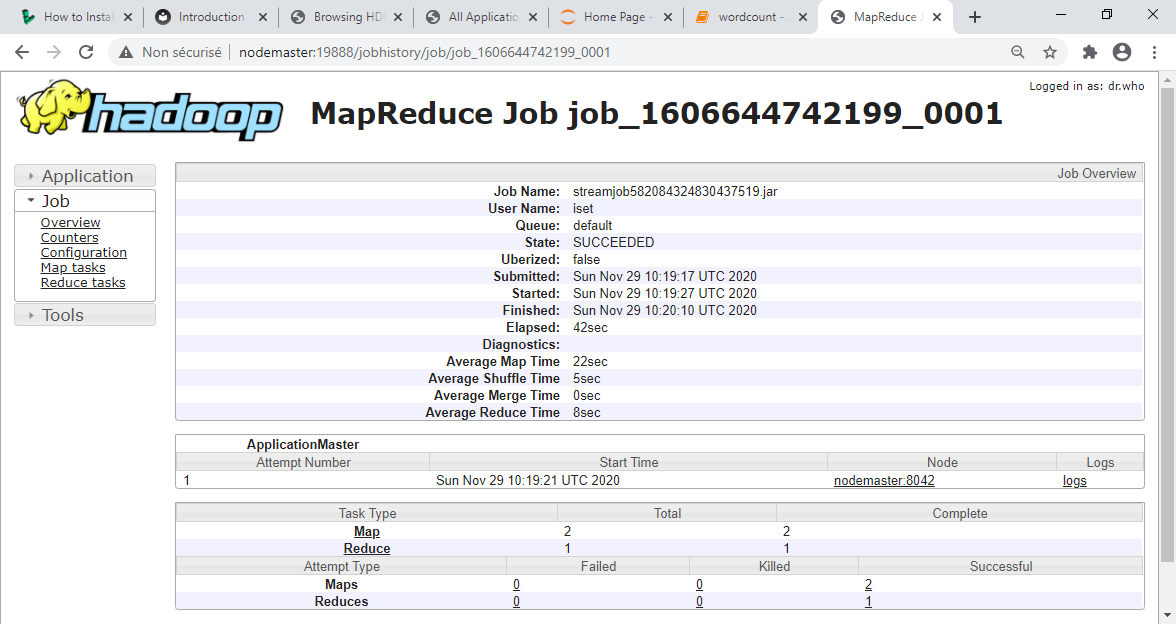
Et puis chacune des tâches :
La première tâche Map 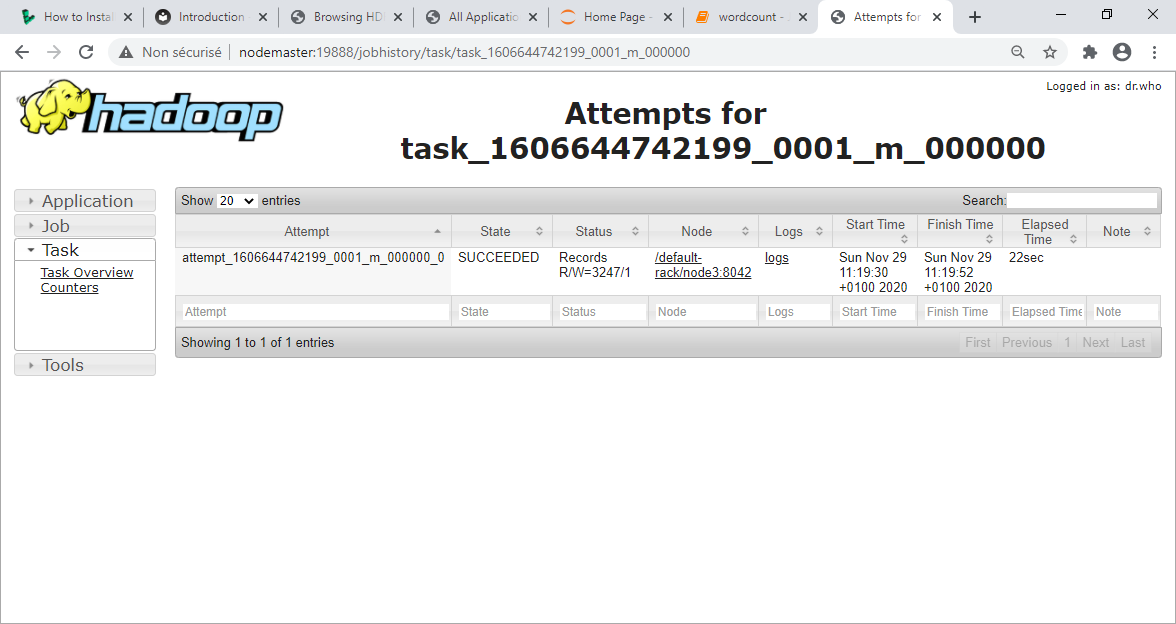
La seconde tâche Map 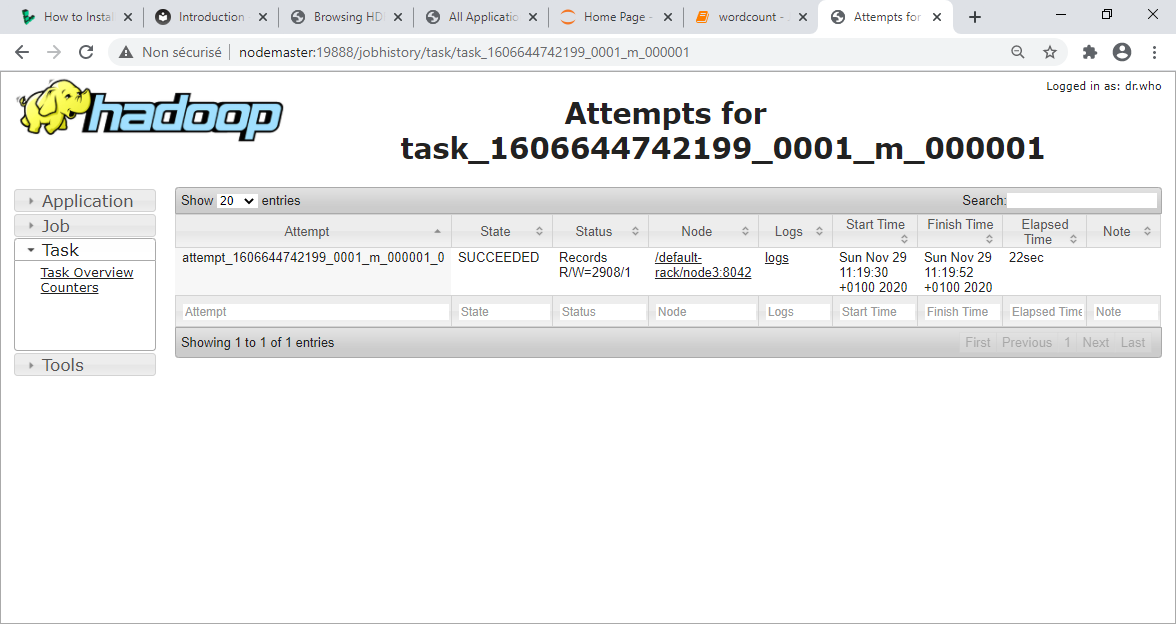
La tâche Reduce