
Manipulation de HDFS¶
Service HDFS¶
Démarrer/Arrêter¶
Service HDFS
Pour gérer les services, il est recommandé d'utiliser le script SelectService. Mais pour les gérer individuellement il est possible d'utiliser les commandes suivantes :
sudo service hadoop-hdfs-namenode start
sudo service hadoop-hdfs-datanode start
sudo service hadoop-hdfs-namenode stop
sudo service hadoop-hdfs-datanode stop
La commande sudo jps permet de vérifier que deux processus sont lancés : NameNode et DataNode. Avec la version 3, un processus SecondaryNameNode est aussi lancé.
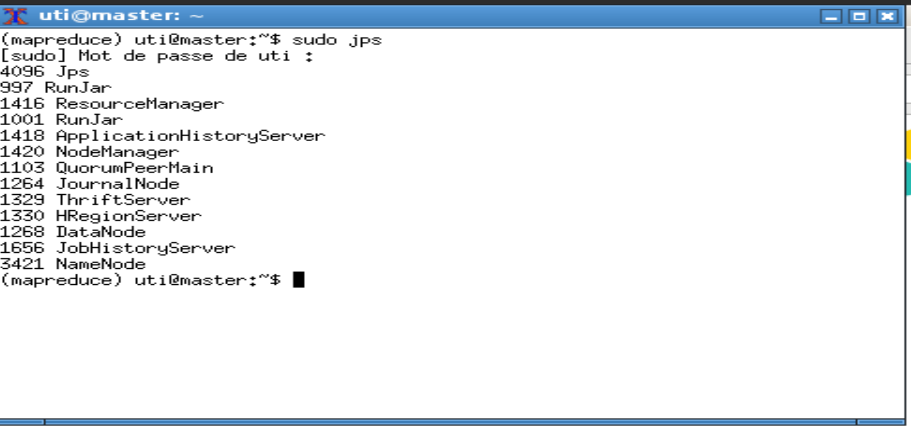
HDFS est maintenant accessible via l'interface web : http://localhost:50070
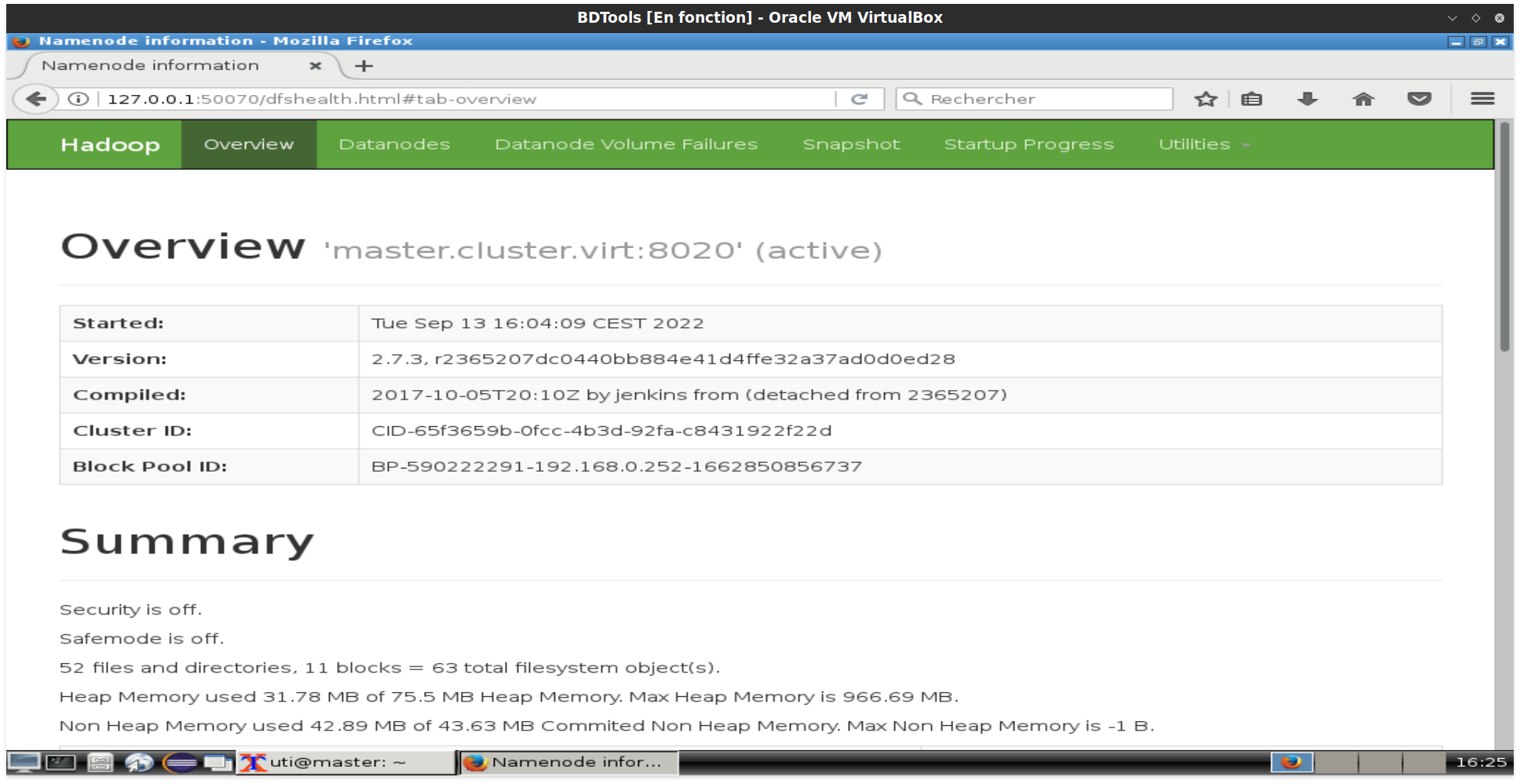
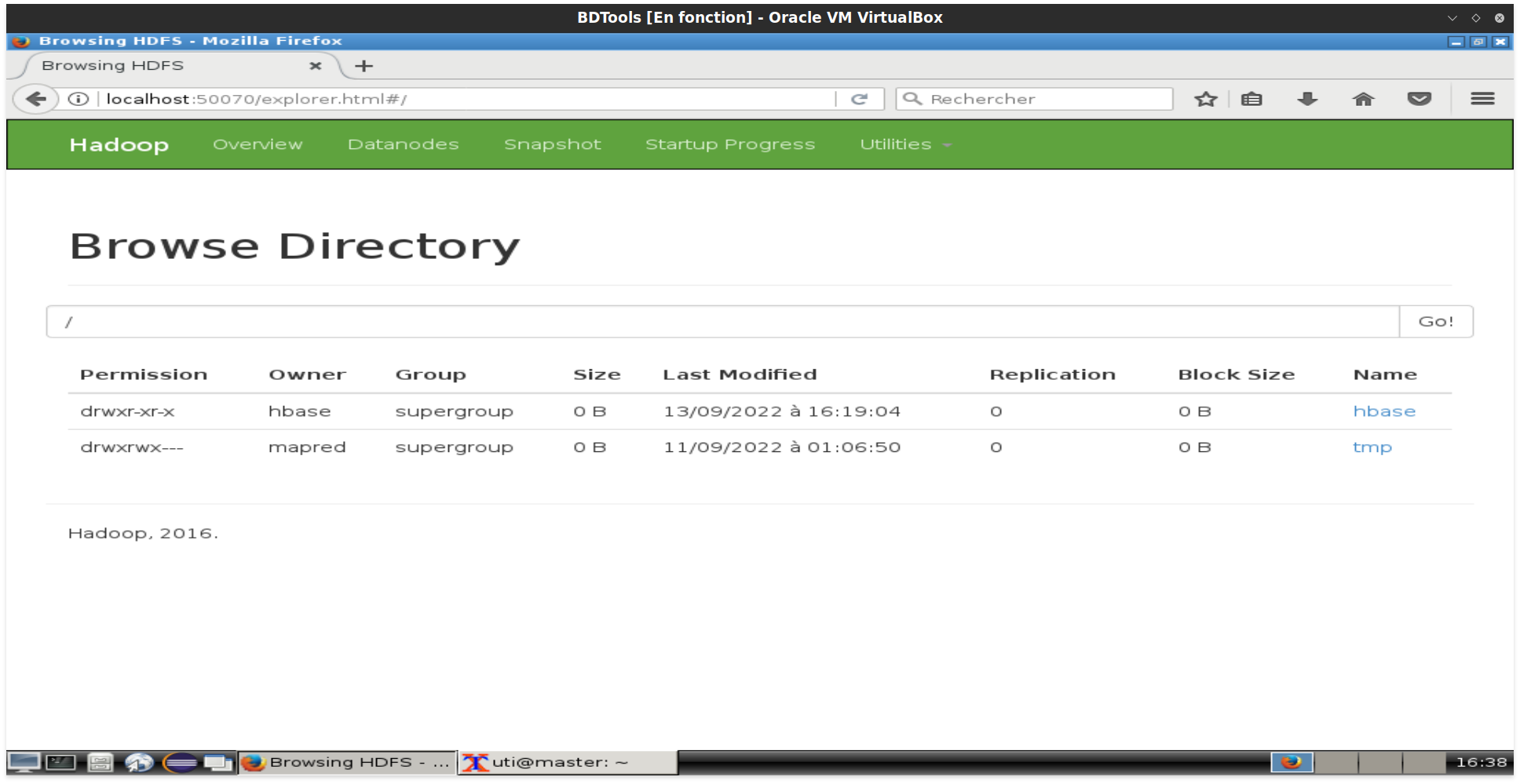
Cette interface permet d'afficher l'état de HDFS et ses diffrents datanodes. Il est possible d'explorer le contenu du système de fichiers à partir du menu Utilities puis Browse the file system.
Formatage¶
hdfs namenode -format
Attention
L'opération de formatage supprime tous les fichiers. Elle est effectuée lors de l'installation de Hadoop ou pour réinitialiser HDFS.
Commandes HDFS¶
Le système HDFS est manipulé à travers des commandes inspirées du système Linux. La forme générale de ces commandes est comme suit :
Format des commandes HDFS
hadoop fs -nomCommande -options param1 ...
Ou encore :
hdfs dfs -nomCommande -options param1 ...
Aide sur une commande¶
Aide sur les commandes HDFS
Afficher les commandes disponibles :
hadoop fs -help
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge [-immediate]]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defswrz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Aide sur une commande HDFS
Afficher l'aide sur une commande particulière (ici la commande ls) :
hadoop fs -help ls
-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...] :
List the contents that match the specified file pattern. If path is not specified, the contents of /user/<currentUser> will be listed.
For a directory a list of its direct children is returned (unless -d option is specified).
Directory entries are of the form:
permissions - userId groupId sizeOfDirectory(in bytes) modificationDate(yyyy-MM-dd HH:mm) directoryName
and file entries are of the form:
permissions numberOfReplicas userId groupId sizeOfFile(in bytes) modificationDate(yyyy-MM-dd HH:mm) fileName
-C Display the paths of files and directories only.
-d Directories are listed as plain files.
-h Formats the sizes of files in a human-readable fashion rather than a number of bytes.
-q Print ? instead of non-printable characters.
-R Recursively list the contents of directories.
-t Sort files by modification time (most recent first).
-S Sort files by size.
-r Reverse the order of the sort.
-u Use time of last access instead of modification for display and sorting.
-e Display the erasure coding policy of files and directories.
Exemples :  ¶
¶
 Affichage du contenu d'un dossier¶
Affichage du contenu d'un dossier¶
hadoop fs -ls
Dossier par défaut
Pour les chemins relatifs HDFS utilise /user/nom_utilisateur comme racine ou nom_utilisateur est l'utilisateur connecté. Si le dossier /user/<nom utilisateur> n'est pas créé, cette commande provoque une erreur. Dans notre cas, c'est le dossier /user/uti qui doit être créé.
hadoop fs -mkdir -p .
hadoop fs -mkdir -p /user/uti
 Créer des fichiers¶
Créer des fichiers¶
Créer un fichier test.txt
hadoop fs -touchz test.txt
 Upload de fichiers ou dossiers¶
Upload de fichiers ou dossiers¶
Upload de fichier
Le fichier exemple.txt doit être dans le dossier en cours. (Utiliser Geany ou autre éditeur pour le créer)
hadoop fs -put exemple.txt
hadoop fs -copyFromLocal exemple.txt
Pour choisir une taille de bloc différente de celle par défaut :
hadoop fs -D dfs.blocksize=268435456 -put exemple.txt exemple_256M.txt
 Supprimer des fichiers¶
Supprimer des fichiers¶
Supprimer le fichier test.txt
hadoop fs -rm test.txt
 Créer des dossier¶
Créer des dossier¶
Créer un dossier data/csv
hadoop fs -mkdir -p data/csv
 Supprimer des dossiers¶
Supprimer des dossiers¶
Supprimer le dossier csv
hadoop fs -rmdir csv
 Copier/déplacer des fichiers ou des dossiers¶
Copier/déplacer des fichiers ou des dossiers¶
Copier le fichier test.txt
hadoop fs -cp test.txt data/copie.txt
Déplacer le fichier copie.txt
hadoop fs -mv data/copie.txt copie2.txt
 Créer un fichiers avec plusieurs blocs¶
Créer un fichiers avec plusieurs blocs¶
Créer un fichier de taille 100MO sur HDFS
dd if=/dev/zero of=test.img bs=1024 count=0 seek=100M
hdfs dfs -put test.img
Maintenant vérifier sur l'interface Web les blocs. (7 blocs pour un bloc de taille 16M)
Autres Commandes ¶
Ajouter dans un fichier¶
à partir du STDIN
hadoop fs -appendToFile - copie2.txt
echo "nouvelle ligne" >new.txt
hadoop fs -appendToFile new.txt copie2.txt
Changer les permissions¶
hadoop fs -chmod 644 copie2.txt
Changer le propriétaire¶
hadoop fs -chown root:root copie2.txt
Récupérer le contenu d'un dossier dans un fichier¶
hadoop fs -getmerge -nl data resultat.txt
Afficher des statistiques¶
hadoop fs -stat "type:%F perm:%a %u:%g size:%b mtime:%y atime:%x name:%n block:%o replication:%r" exemple.txt
Changer le facteur de replication¶
hadoop fs -setrep 5 exemple.txt
Administration¶
hdfs getconf -confKey
# Exemples
hdfs getconf -namenodes
hdfs getconf -secondaryNameNodes
hdfs getconf -confKey [key]
hdfs dfsadmin [-report [-live] [-dead] [-decommissioning] [-enteringmaintenance] [-inmaintenance] [-slownodes]]
hdfs dfsadmin [-safemode enter | leave | get | wait | forceExit]
hdfs dfsadmin [-printTopology]
hdfs dfsadmin [-listOpenFiles [-blockingDecommission] [-path <path>]]
hdfs dfsadmin [-allowSnapshot <snapshotDir>]
hdfs fsck <path>
[-list-corruptfileblocks |
[-move | -delete | -openforwrite]
[-files [-blocks [-locations | -racks | -replicaDetails | -upgradedomains]]]
[-includeSnapshots] [-showprogress]
[-storagepolicies] [-maintenance]
[-blockId <blk_Id>] [-replicate]
hdfs namenode [-backup] |
[-checkpoint] |
[-format [-clusterid cid ] [-force] [-nonInteractive] ] |
[-upgrade [-clusterid cid] [-renameReserved<k-v pairs>] ] |
[-upgradeOnly [-clusterid cid] [-renameReserved<k-v pairs>] ] |
[-rollback] |
[-rollingUpgrade <rollback |started> ] |
[-importCheckpoint] |
[-initializeSharedEdits] |
[-bootstrapStandby [-force] [-nonInteractive] [-skipSharedEditsCheck] ] |
[-recover [-force] ] |
[-metadataVersion ]
# Administration Erasure Coding
hdfs ec [generic options]
[-setPolicy -path <path> [-policy <policyName>] [-replicate]]
[-getPolicy -path <path>]
[-unsetPolicy -path <path>]
[-listPolicies]
[-addPolicies -policyFile <file>]
[-listCodecs]
[-enablePolicy -policy <policyName>]
[-disablePolicy -policy <policyName>]
[-removePolicy -policy <policyName>]
[-verifyClusterSetup -policy <policyName>...<policyName>]
[-help [cmd ...]]
Exercices¶
Exercice 1  ¶
¶
- Sur HDFS, créer l'arborescence tunisie/petrole.
- Chercher et télécharger, sur http://data.gov.tn, les données sur la production pétrolière mensuelle par champ dans le format CSV.
- Placer le fichier dans le dossier petrole créé dans la première étape.
- À partir de l'interface web :
- Chercher la taille du bloc par défaut.
- Copier sur HDFS un fichier plus grand que la taille du bloc et vérifier le nombre de blocs de ce fichier.
Exercice 2 ¶
- Afficher les fichiers des sous-dossiers, avec une taille arrondie en Ko, Mo ou Go.
- Créer un dossier dans le répertoire racine du HDFS.
- Créer un fichier appelé hello-hadoop.txt dans le compte Linux et contenant la phrase « Hello Hadoop ».
- Copier ce fichier sur HDFS.
- Vérifier le résultat.
- Afficher le contenu du fichier.
- Afficher le dernier Ko du fichier.
- Supprimer ce fichier de HDFS.
- Remettre à nouveau ce fichier et vérifier le résultat.
- Transférer le fichier hello-hadoop de HDFS vers le compte Linux en lui changeant son nom.
- Positionner le facteur de réplication à 2 pour le fichier hello-hadoop.txt.
- Vérifier avec la commande stat.
- Changer les permissions sur le fichier hello-hadoop.txt à 777.
- Ajouter du texte "HDFS est un système de fichiers distribué." au fichier hello-hadoop.txt sur HDFS.