
Débuter avec l'écosystème Hadoop¶
Objectifs¶
- Gérer et vérifier les services de Hadoop
- Manipuler le système de fichiers HDFS
- Comprendre et créer des programmes MapReduce simples
- Créer des programmes MapReduce à plusieurs phases
- Transformer et Interroger les données avec Pig et Hive
- Déployer un cluster Hadoop
Ressources¶
Outils
- Oracle Virtual Box V6 ou plus (ou VMware)
- Image de machine virtuelle avec les outils pré-installés. C'est une image créée par Pierre Nezric à laquelle sont ajoutés jupyter et mrjob. Elle contient les outils suivants :
- Hadoop 2.7.3
- Spark 2.1.1
- Pig 0.15.0
- Hive 1.2.1
- HBase 1.1.9
- Cassandra
- Elasticsearch et Kibana
- Zookeeper 3.4.6
Sources et référence

Présentation de Hadoop¶
Rôle¶
Hadoop est un framework pour le stockage et le traitement distribué de grands volumes de données sur des clusters d'ordinateurs à l'aide de modèles de programmation simples. Il permet de passer de nœuds uniques à des milliers de machines, chacune offrant un calcul et un stockage locaux. Hadoop garantit une haute disponibilité en détectant et traitant les pannes au niveau de la couche application.
Hadoop supporte la scalabilité horizontale et verticale. Il est la plateforme Big Data de référence.
Historique et versions¶
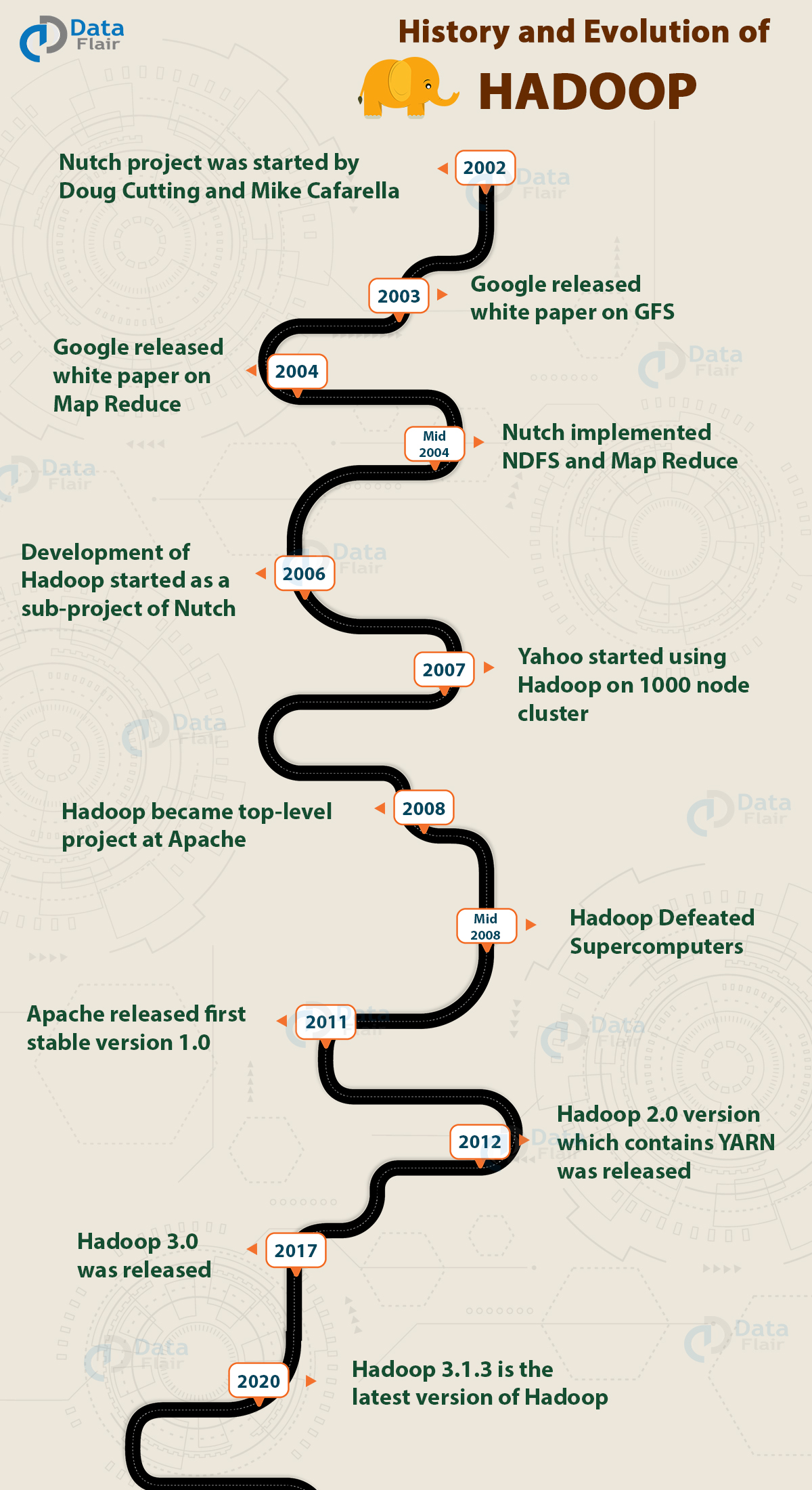
Les principales nouveautés des versions majeures par rapport aux versions précédentes sont :
Version 2 :
- YARN : la gestion des ressources du cluster.
Version 3 :
- Erasure Coding : tolérance aux fautes par bloc de parité.
- Haute disponibilité améliorée avec plusieurs NameNode secondaires (en standby)
Comment obtenir Hadoop ?
Hadoop est projet Open Source avec la licence Apache V2. Mais il existe aussi des distributions commerciales offertes par des fournisseurs avec des outils supplémentaires pour former une plateforme de Big Data Analytics. Historiquement, les leaders sont Cloudera, Hortonworks et MapR. Mais ces dernières années, plusieurs acquisitions et fusions ont été effectuées.
Les principales alternatives actuelles pour obtenir Hadoop sont :
- Apache Hadoop : C'est la version Open Source. Plus difficile à gérer pour composer un écosystème complet malgré que la majorité des composants sont Open Source aussi (Spark, Flink, Hive, Hbase, ...).
- Distribution Hadoop : où une pile de composants sont pré-installé avec des outils de gestion et d'administration intégrés (Ambari, Clouder Manager, ...). Parmi ces distributions on trouve :
- Cloudera : après la fusion, en 2018, avec son concurrent direct Hortonworks il a hérité de ces produits HDP (Hortonworks Data Platform) et HDF (Hortonworks Data Flow) sous forme de machines virtuelles (VMware, VirtualBox et Docker) et CDP (Cloudera Data Platform) en Cloud.
- Hewlett Packard Enterprise : qui hérite de la plateforme MapR Data Platform après son acquisition en 2018. Elle est rebaptisée sous le nom HPE Ezmeral Data Fabric V6.2 (voir comment l'installer ici). Elle est compatible avec Ubuntu, RedHat/CentOS et SUSE. Un version légère pour le développement et test est aussi offerte sous la forme d'un container Docker (Development Environment for HPE Ezmeral Data Fabric).
- IBM Open Platform: IOP ou IBM BigInsights est la distribution d'IBM disponible en version de production ou de test (Quick Start Edition).
- Équipement dédié : Matériel optimisé pour Hadoop comme : Dell, EMC, Teradata Appliance for Hadoop, HP, Oracle, ...
- Hadoop sur le Cloud: comme PaaS (Platform as a Service) tel que Amazon EMR, Microsoft HDInsight, Google Cloud Platform, Qubole, IBM BigInsights, ...
Cloudera Data Platform
Pour tester une liste plus étendue d'outils de l'écosystème Hadoop, je vous recommance la distribution Cloudera Data Platform 3.0 ou 2.6. Il faut lui prévoir plus de ressources RAM et disque.
Composants du noyau Hadoop¶
3 composants principaux sont au cœur de Hadoop :

HDFS (Hadoop Distributed File System)¶
C'est le système de fichier primaire de Hadoop. Il permet le stockage de larges volumes de données sur des unités de stockage assez basique et abordable. Les données sont partitionnées et répliquées pour garantir la fiabilité et un accès parallèle. Il opère selon le modèle maître-esclave formé respectivement par les nœuds NameNode et DataNode.
MapReduce¶
C'est la couche de traitement dans Hadoop. Elle traite des volumes importants de données structurées et non structurées stockées dans HDFS. MapReduce traite également une énorme quantité de données en parallèle. Pour ce faire, il divise le travail en un ensemble de tâches indépendantes selon le principe divisier et conquérir. MapReduce fonctionne en divisant le traitement en phases: Map et Reduce.
YARN (Yet Another Resource Negotiator)¶
Il s'occupe de la gestion et la surveillance des travaux. YARN permet plusieurs moteurs de traitement de données tels que le streaming en temps réel, le traitement par lots, etc. Le Resource Manager est le composant au niveau de la machine maître. Il gère les ressources et planifie les applications s'exécutant sur YARN. Il a deux composants: Scheduler & Application Manager. Tandis que le Node Manager, au niveau du nœud, communique en permanence avec Resource Manager et assure l'exécution des tâches.