
MapReduce en Python¶
Démarrage/Arrêt du service¶
Service YARN
sudo service hadoop-yarn-resourcemanager start
sudo service hadoop-yarn-nodemanager start
sudo service hadoop-yarn-resourcemanager stop
sudo service hadoop-yarn-nodemanager stop
La commande jps permet de vérifier que deux processus sont lancés : ResourceManager et NodeManager.
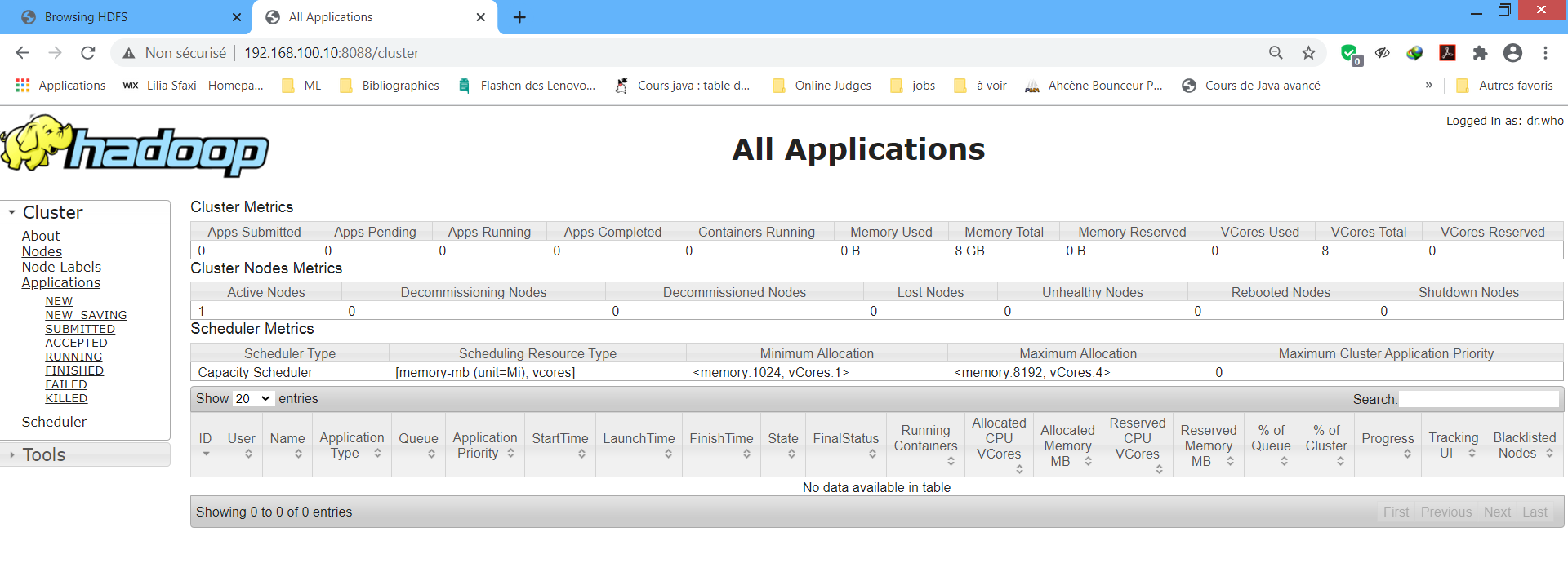
L'interface du Resource Manager est accessible depuis : http://localhost:8088 Cette interface permet de vérifier l'état des ressources RAM et CPU du cluster, les applications (démarrées, terminées, en cours ...) et les noeuds du cluster.
Vérification des processus serveur¶
Pour voir les différents processus serveurs, exécuter la commande jps. Le résultat est :
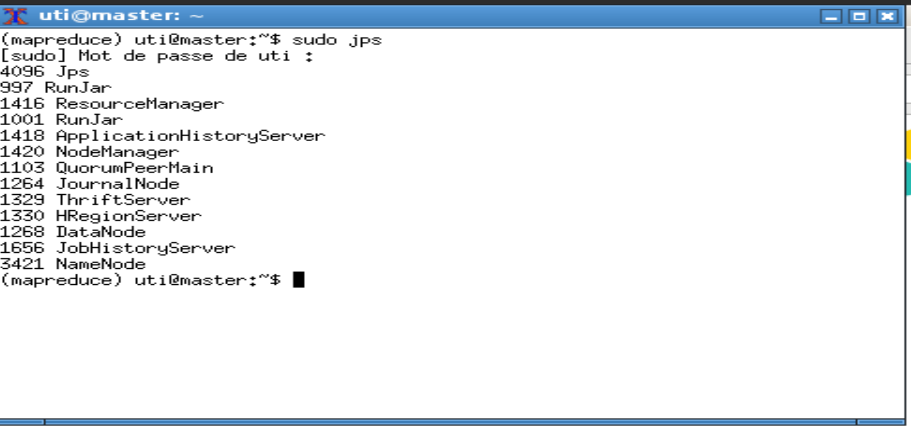
- Processus HDFS : NameNode, DataNode, JournalNode
- Processus YARN : ResourceManager, NodeManager, JobHistoryServer, ApplicationHistoryServer
Préparer l'environnement¶
Pour les exemples et les exercices de cette section, vous avez besoin de Python, Jupyter et MRJOB.
 Installer les paquets et modules suivants :
Installer les paquets et modules suivants :
Cette étape est à ignorer si vous utilisez la machine virtuelle fournie.
$ sudo apt-get install python python3-pip
$ sudo pip3 install mrjob
$ sudo pip3 install jupyter
 Lancer Jupyter Notebook
Lancer Jupyter Notebook
$ cd dossier_travail
$ jupyter notebook --no-browser --ip=0.0.0.0 --NotebookApp.token=''
Pour accéder depuis la machine hôte aller à l'adresse : http://localhost:8888
Les exemples peuvent être écrits avec un simple éditeur comme geany, nano, vi (ou encore notepad sous windows). Et les commandes peuvent être lancées à partir du shell.
Premier Exemple : Word Count¶
L'exemple classique pour illustrer le fonctionnement de MapReduce est celui de compter le nombre d'occurences d'un mot dans un fichier texte (le fichier shakespeare.txt .)
Étapes à suivre¶
Pour exécuter un job MapReduce, il faut généralement suivre les étapes suivantes :
- Placer le fichier de données ou dataset dans le système HDFS via la commande
hadoop fs -put ... - Écrire le code source .py
- Soumettre le job MapReduce :
- Par Hadoop Streaming : Avec la commande
hadoop jar hadoop-streaming.jar -input <input_file> -output <resultat> -mapper <mapper.py> -reducer <reducer.py> - Par MRJob : Avec la commande
python <programme.py> -r hadoop <input_file>
- Par Hadoop Streaming : Avec la commande
Mapper et Reducer¶
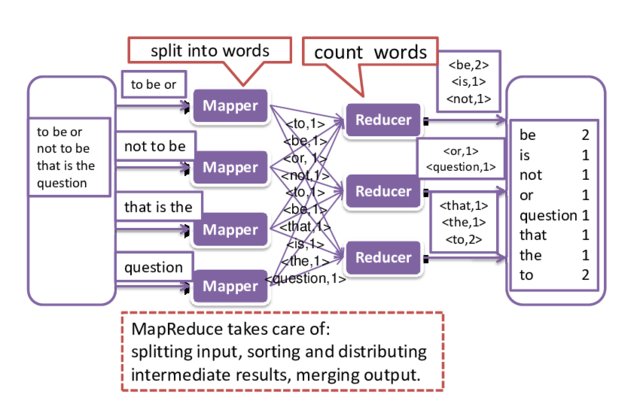
L'objectif est de déterminer le nombre d'occurences de chaque mot du fichier. Chaque ligne est composée de plusieurs mots (Le séparateur est ' ').
La transformation à effectuer par chaque Mapper est de décomposer chaque ligne reçue en mots est lui associer la valeur 1.
Après la phase de tri et de redistribution (sort and shuffle), chaque Reducer va recevoir des mots et une liste de '1' pour chaque occurence. Pour calculer le nombre d'occurences total, il suffit de faire la somme de ces '1'.
Programmation avec MRJob¶
MapReduce est écrit en Java mais accepte les autres langages de programmation via la technique de streaming via opération de lecture écriture sur les flux d'entrée-sortie standard (print, read).
La bibliothèque mrjob simplifie l'écriture de programmes MapReduce.
Dans cet exemple, deux classes de la librairie mrjob sont utilisées : MRJob et MRStep.
- Pour créer un Job MapReduce, il suffit de créer une classe qui hérite de MRJob (ici la classe WordCount).
- Créer une fonction qui effectue la transformation du Mapper : la méthode
mapper_get_words. Cette méthode reçoit 3 paramètres self comme toutes les méthodes d'une classe, le deuxième est ignoré pour ce mapper et le dernier c'est une ligne du fichier de données. La fonction split décompose la ligne en une liste de mots. - Créer une fonction qui réalise l'agrégation du Reducer : la méthode
reducer_count_words. Elle reçoit le paramètre self, la clé utilisée par le Mapper (donc un mot) et la liste des valeurs récuprées des différents mappers (les '1'). L'agrégation effectuée est une somme par la fonction sum. - Définier les étapes ou les différentes tâche à effectuer dans une méthode appelée
stepsqui doit retouner une liste de MRStep. Pour chaque instance MRStep créée, on spécifie le nom de la fonction mapper et reducer déjà définie. Dans cet exemple, il y a une seule phase MapReduce. - Enfin l'appel de la méthode
runpour déclencher L'exécution du Job MapReduce.
Exécuter votre premier Job MapReduce  ¶
¶
Démarrer la machine virtuelle.
Télécharger (dans la machine virtuelle) le notebook wordcount.ipynb
 Depuis un terminal, lancer jupyter dans le dossier pour exécuter le notebook :
Depuis un terminal, lancer jupyter dans le dossier pour exécuter le notebook :
jupyter notebook
Dans ce qui suit le contenu du Notebook Jupyter avec le code à tester.
Streaming jar
En cas d'erreur No hadoop streaming jar, donner le chemin vers ce jar avec la commande :
! python wordcount.py -r hadoop --hadoop-streaming-jar C:\hadoop-env\hadoop-3.2.1\share\hadoop\tools\lib\hadoop-streaming-3.2.1.jar hdfs:///user/uti/shakespeare.txt
Surveiller les jobs¶
Pour afficher les jobs MapReduce de la session en cours, visiter la page http://localhost:8088
Quand le programme MapReduce de l'exercice précédent est terminé, il est indiqué dans la capture suivante :
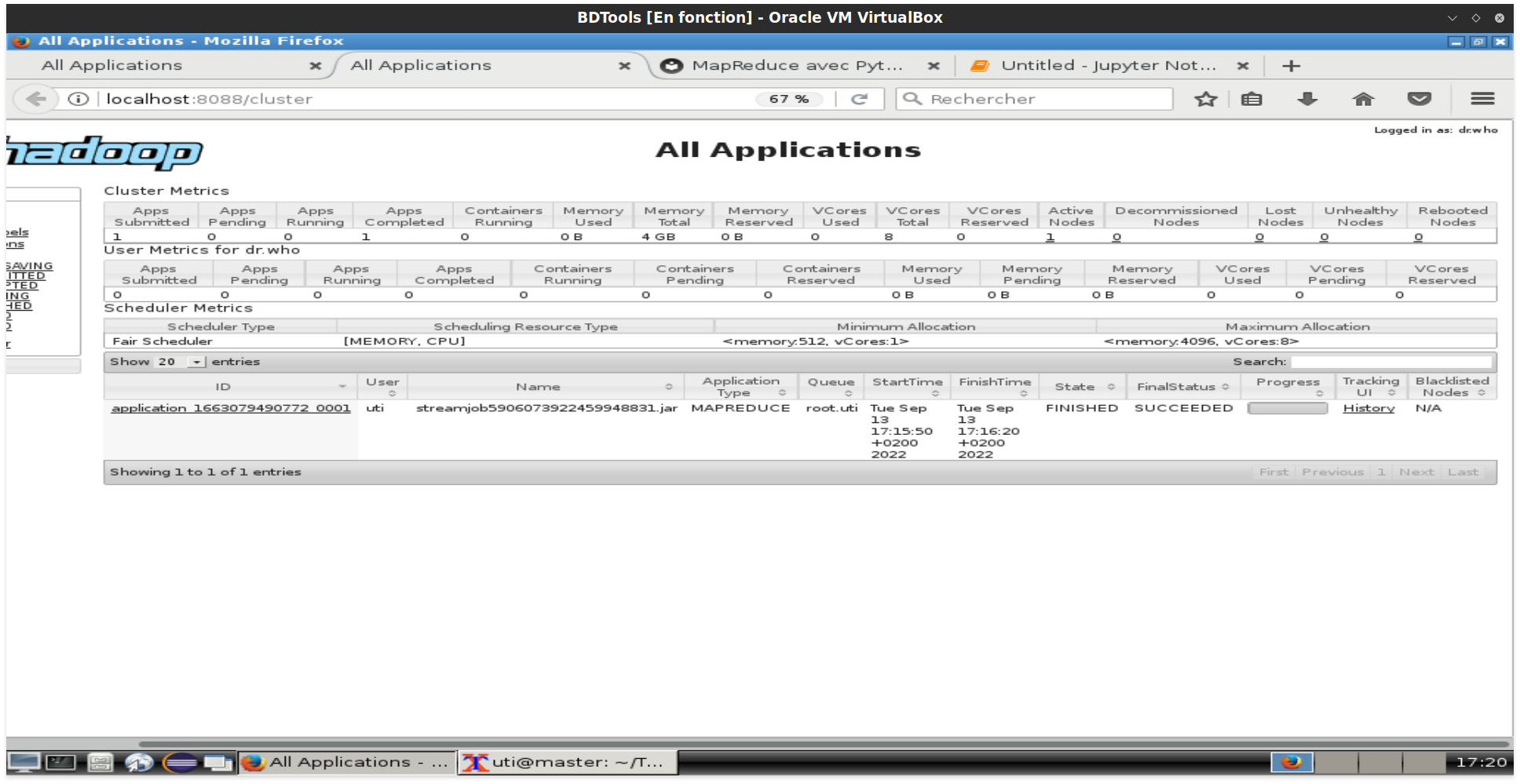
Pour afficher l'historique complet c'est à partir d'ici : http://localhost:8081
Il est aussi possible d'utiliser les commandes yarn :
- Pour afficher toutes les applications :
yarn application -list -appStates ALL - Pour arrêter une application :
yarn application -kill <id>
Exercices¶
Exercice 1  ¶
¶
- Transformer l'exemple WordCount afin d'obtenir le résultat trié dans l'ordre croissant du nombre d'occurrences. (Hint : exploiter la phase sort and shuffle qui trie la clé selon l'ordre alphabétique).
- Transformer le programme pour inverser l'ordre de tri.
Exercice 2 ¶
Sur les données de la production pétrolière de la section précédente et en utilisant MapReduce :
- Calculer la production annuelle de chaque champ.
- Trouver le champ avec la plus grande production par mois.
Exercice 3 ¶
On souhaite afficher pour les utilisateurs d’un réseau social le nombre d’amis en commun avec un autre utilisateur quand il visite la page de ce dernier.
Écrire un programme Map Reduce qui calcule le nombre d’amis en communs pour chaque paire d’utilisateurs sachant qu’on dispose d’un fichier contenant les identifiants des utilisateurs suivis des identifiants de leurs amis.
Le format de chaque ligne de ce fichier est :
Id_utilisateur : id_ami1, id_ami2, ….
Exemple : (réseau social contenant 5 utilisateurs)
10:20,30,40
20:10,30,40
30:10,20,40,50
40:10,20,30,50
50:30,40
 Idée :
Idée :
L’idée consiste à :
- Générer les couples d’amis à partir de chaque ligne (dans l’ordre croissant des clés couple 10-30 au lieu du couple 30-10 par exemple) : La ligne « 10:20,30,40 » génère ainsi : 10-20:20,30,40 10-30:20,30,40 10-40:20,30,40
- Regrouper les couples (même couleur) puis garder les éléments communs des 2 listes (remarquer que chaque couple apparaît exactement 2 fois). 10-20:20,30,40 10-20:10,30,40 10-20:30,40
Exercice 4 ¶
En s'inspirant de l'exemple MapReduce et source json (books.json ) ci-après qui affiche les titres des livres ayant 700 pages, écrire un programme MapReduce qui calcule le nombre de livres pour chaque auteur.
from mrjob.step import MRStep
from mrjob.job import MRJob
from mrjob.protocol import JSONValueProtocol
class Exemple(MRJob):
INPUT_PROTOCOL = JSONValueProtocol
def steps(self):
return [MRStep(mapper=self.fmap, reducer=self.freduce)]
def fmap(self, _, book):
if book['pageCount']>700:
yield None,(book['title'], book['pageCount'])
def freduce(self, _ ,v):
for l in v:
yield l[0], l[1]
if __name__ == '__main__':
Exemple.run()