
MapReduce en Java¶
Démarrage/Arrêt du service¶
Service YARN
sudo service hadoop-yarn-resourcemanager start
sudo service hadoop-yarn-nodemanager start
sudo service hadoop-yarn-resourcemanager stop
sudo service hadoop-yarn-nodemanager stop
La commande jps permet de vérifier que deux processus sont lancés : ResourceManager et NodeManager.
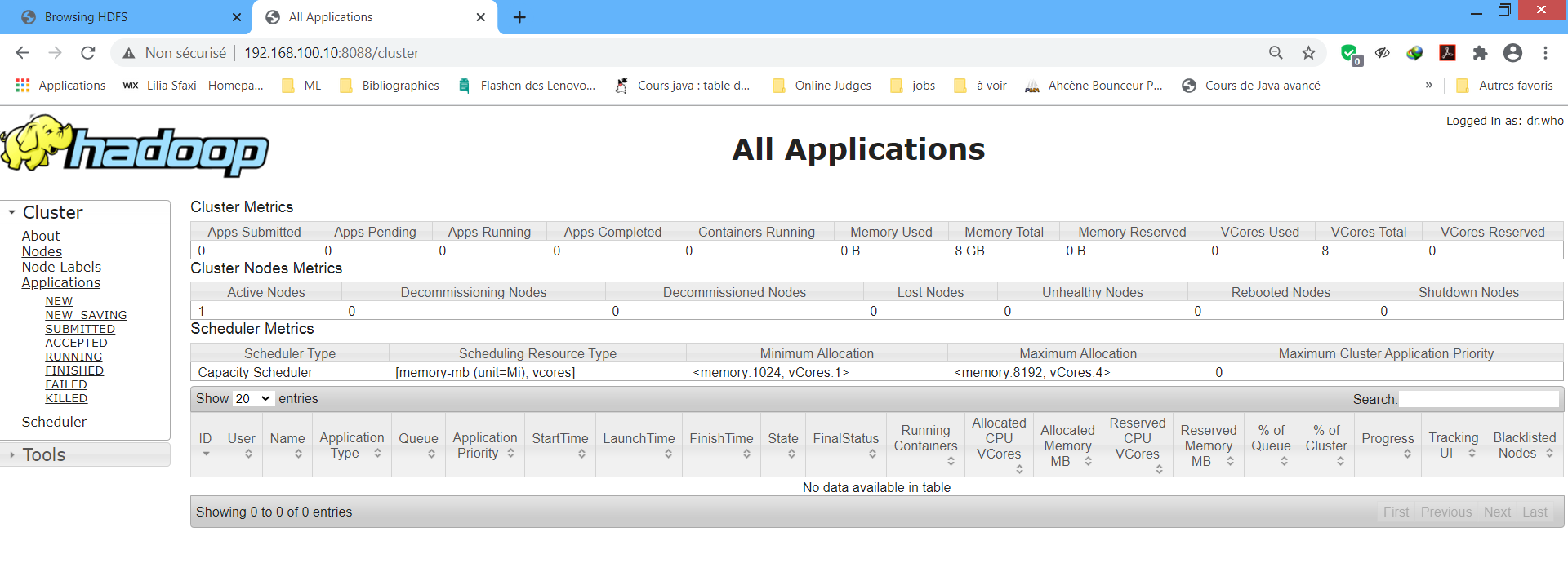
L'interface du Resource Manager est accessible depuis : http://localhost:8088 Cette interface permet de vérifier l'état des ressources RAM et CPU du cluster, les applications (démarrées, terminées, en cours ...) et les noeuds du cluster.
Vérification des processus serveur¶
Pour voir les différents processus serveurs, exécuter la commande jps. Le résultat est :
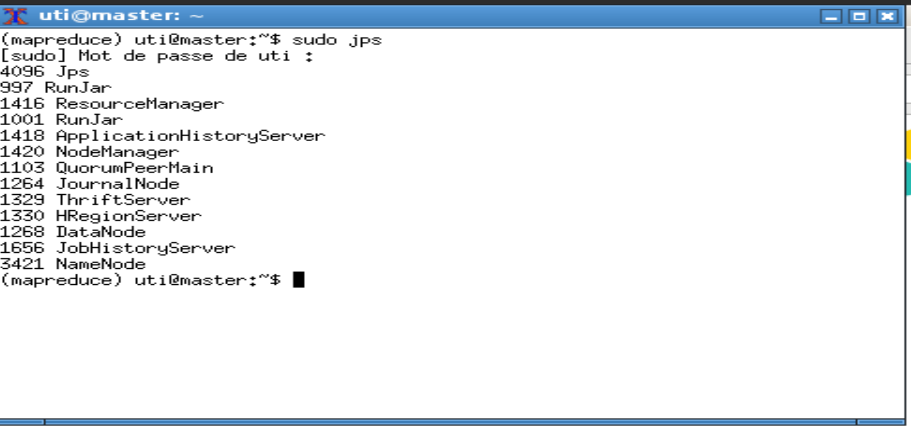
- Processus HDFS : NameNode, DataNode, JournalNode
- Processus YARN : ResourceManager, NodeManager, JobHistoryServer, ApplicationHistoryServer
Premier Exemple : Word Count  ¶
¶
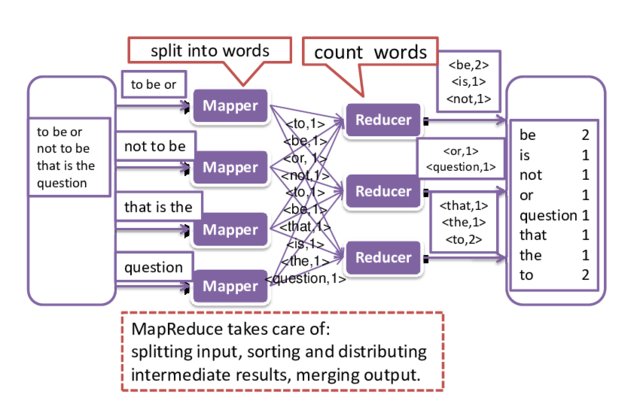
L'exemple classique pour illustrer le fonctionnement de MapReduce est celui de compter le nombre d'occurences d'un mot dans un fichier texte (le fichier shakespeare.txt .)
 Placer le fichier shakespeare.txt dans
Placer le fichier shakespeare.txt dans /home/uti/wordcount/input.
 Démarrer Eclipse dans la machine virtuelle.
Démarrer Eclipse dans la machine virtuelle.
 Créer un nouveau projet de type Maven Project.
Créer un nouveau projet de type Maven Project.
Maven
Le plugin Maven pour Eclipse doit être installé. Maven est utilisé pour gérer les dépendances des projets Java.
 Cocher l'option Projet simple.
Cocher l'option Projet simple.
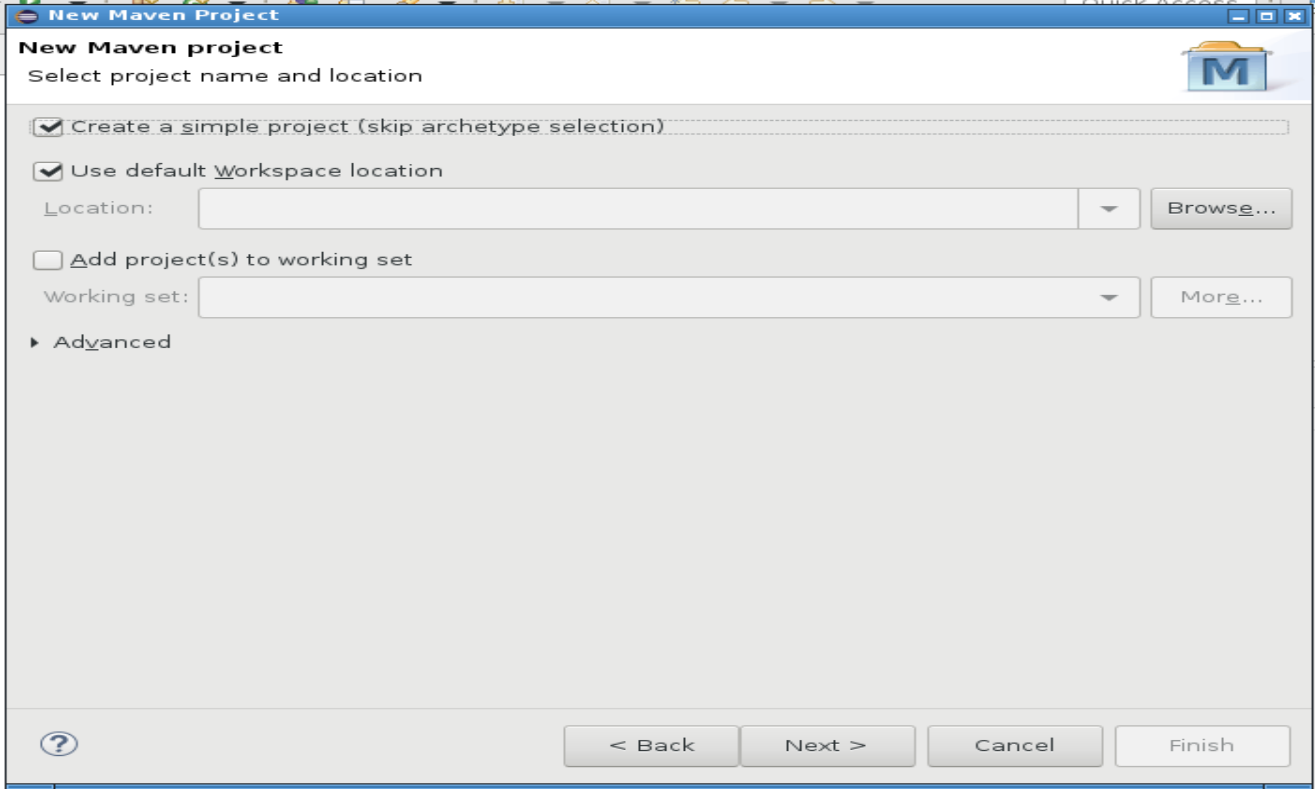
 Remplir Group Id et Artefact Id.
Remplir Group Id et Artefact Id.
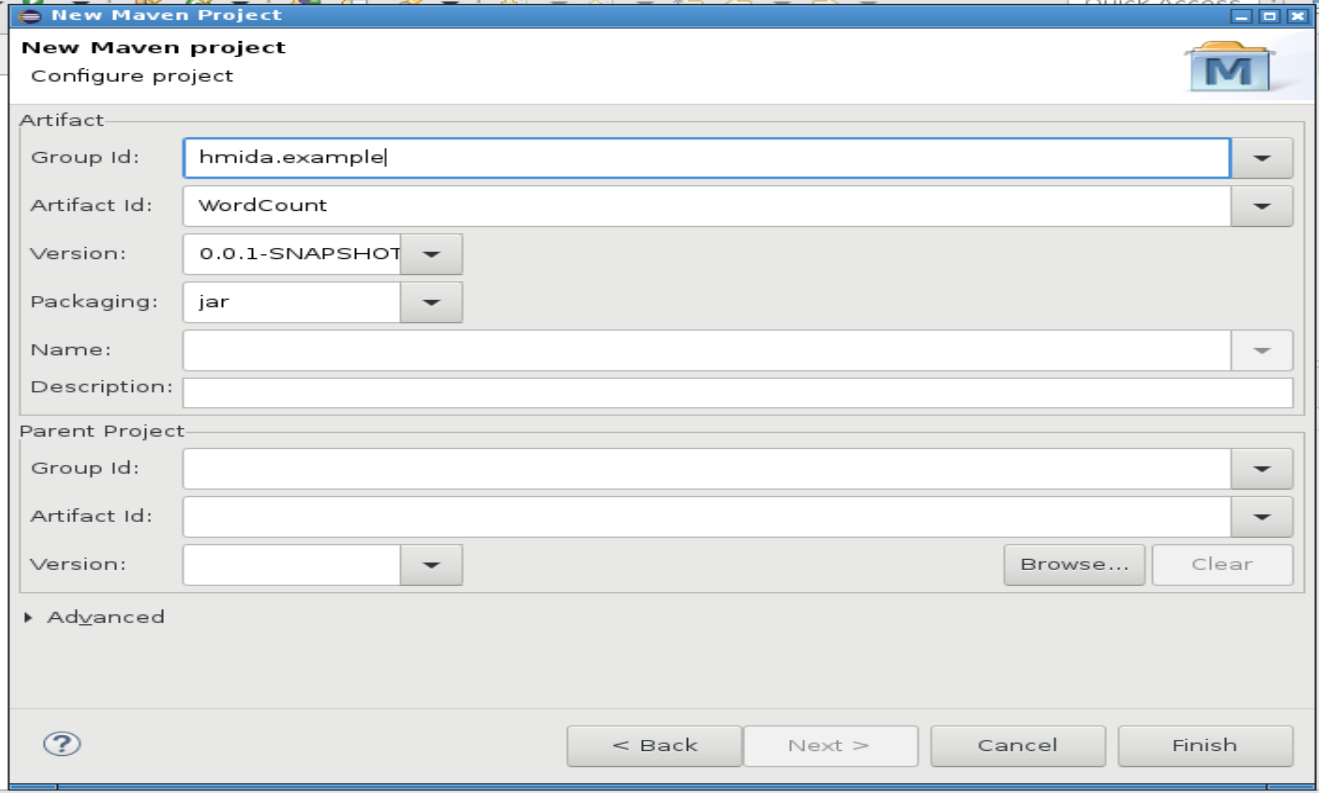
 Créer une nouvelle classe appelée WordCount dans src/main/java.
Créer une nouvelle classe appelée WordCount dans src/main/java.
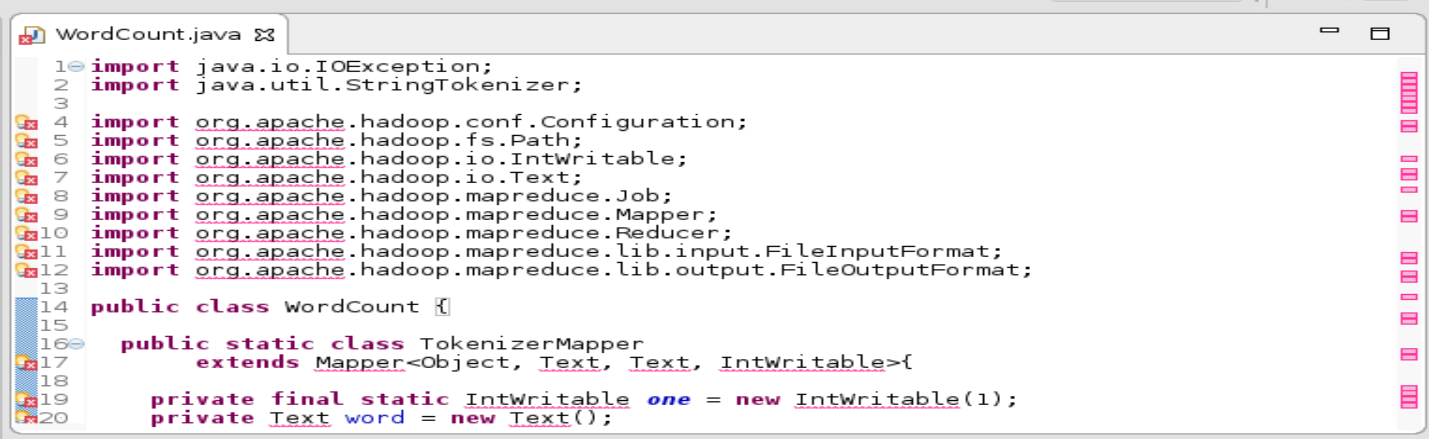
 Placer le code ci-dessous dans la classe créée.
Placer le code ci-dessous dans la classe créée.
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
 Ouvrir le fichier pom.xml en ajoutant les dépendances des bibliothèques Hadoop.
Ouvrir le fichier pom.xml en ajoutant les dépendances des bibliothèques Hadoop.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>hmida.example</groupId>
<artifactId>WordCount</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-shuffle</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
</project>
Dépendances
Dans cet exemple, la version de Hadoop est 2.7.3. Pour d'autres version, les dépendances peuvent être obtenues en recherchant dans Maven Repository.
 Ajouter une configuration d'exécution Dans Eclipse à partir de Run->Run Configuration puis créer un nouvelle configuration. Ensuite ajouter les 2 arguments du programme pour les chemins des fichiers de données et dossier de sortie.
Ajouter une configuration d'exécution Dans Eclipse à partir de Run->Run Configuration puis créer un nouvelle configuration. Ensuite ajouter les 2 arguments du programme pour les chemins des fichiers de données et dossier de sortie.
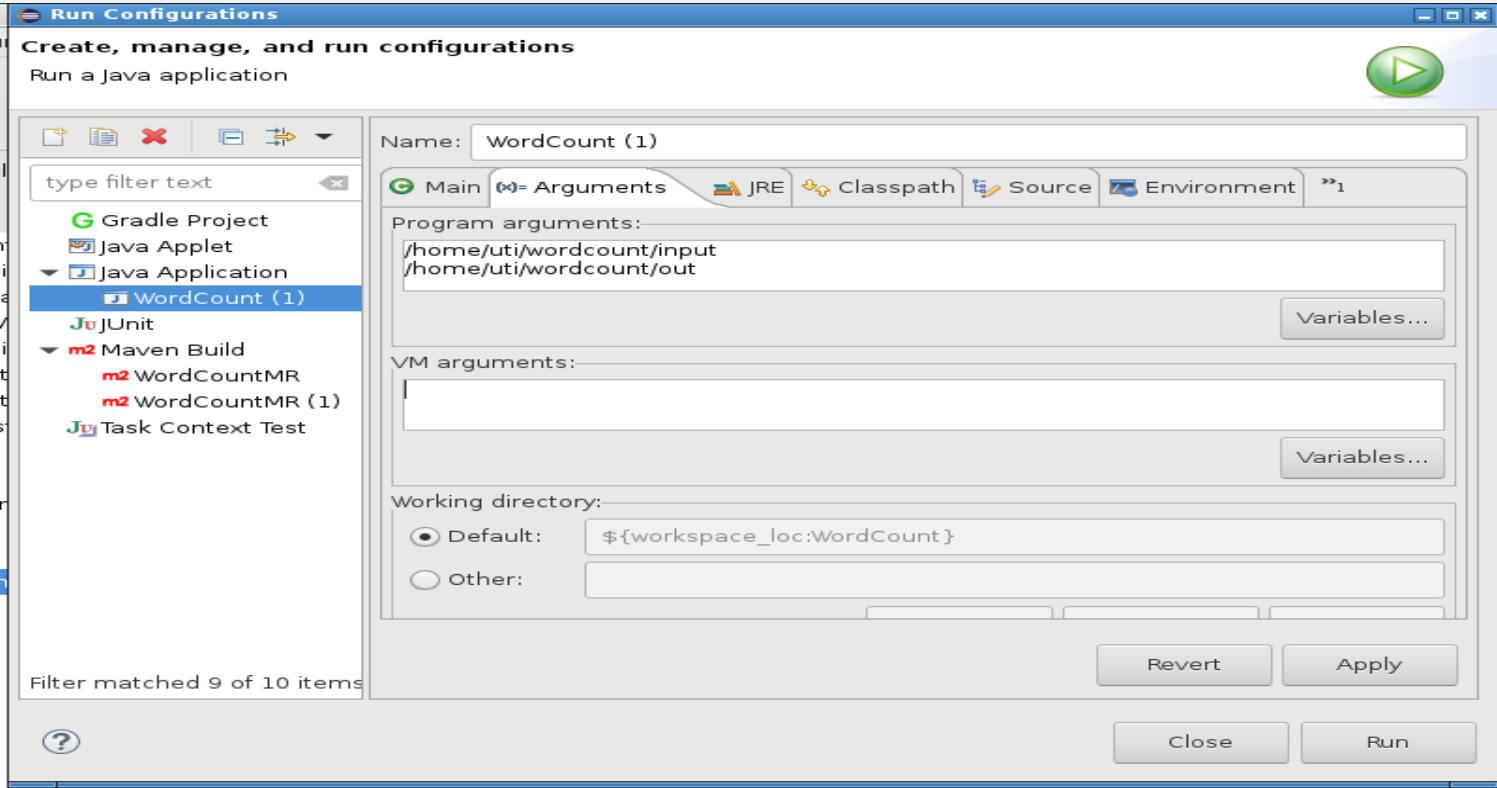
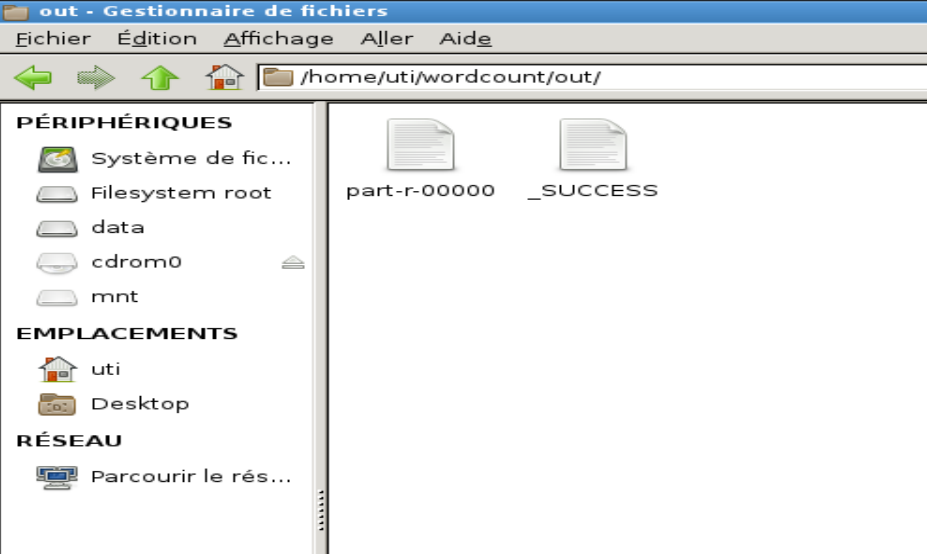
 Cliquer sur Run pour exécuter le programme en local et ensuite vérifier le contenu du dossier de sortie.
Cliquer sur Run pour exécuter le programme en local et ensuite vérifier le contenu du dossier de sortie.
Log4j
Si vous avez des messages d'avertissement concernant Log4j et souhaitez les éliminer alors ajouter dans main\resources le fichier log4j.properties contenant :
log4j.rootLogger=ERROR,stdout
log4j.logger.com.endeca=INFO
# Logger for crawl metrics
log4j.logger.com.endeca.itl.web.metrics=INFO
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%p\t%d{ISO8601}\t%r\t%c\t[%t]\t%m%n
Créer un fichier jar du projet
Menu contextuel du projet->Run As->Maven Install
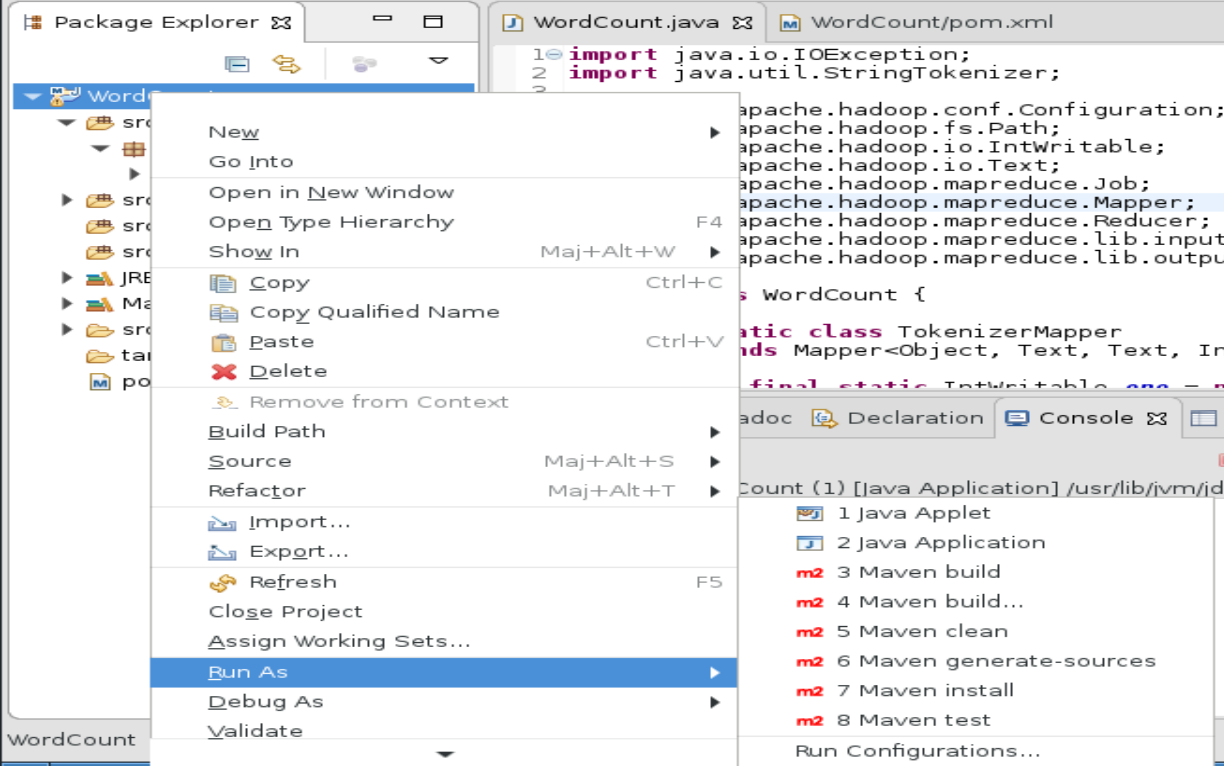
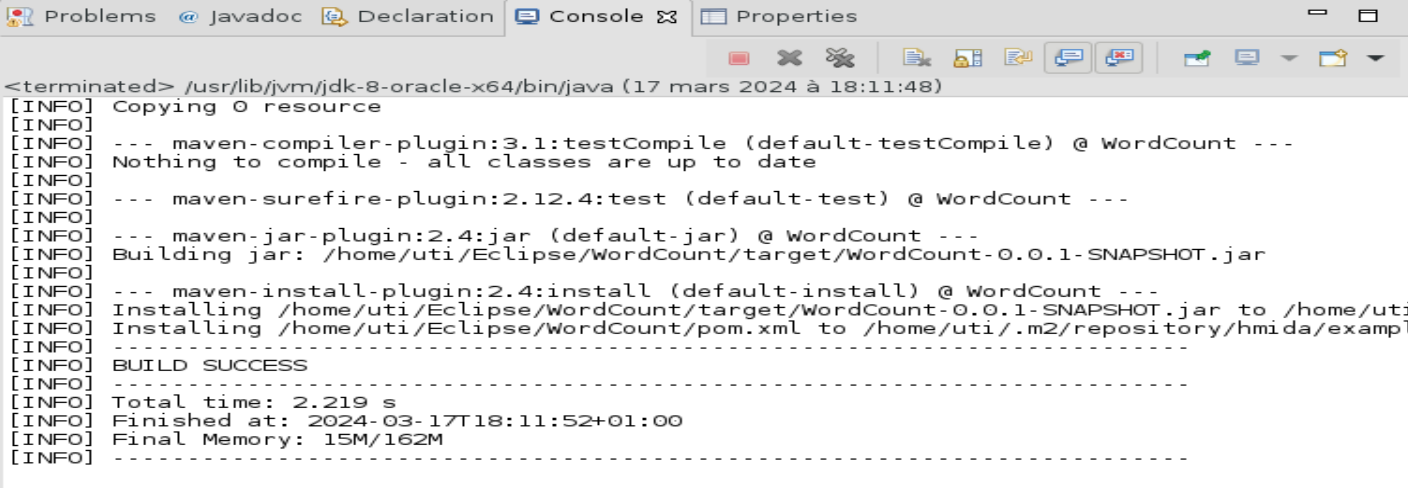
Placer les données sur HDFS
hdfs dfs -mkdir -p wordcount/input
hdfs dfs -put shakespeare.txt wordcount/input
Soumettre un job MapReduce
hadoop jar WordCount-0.0.1-SNAPSHOT.jar WordCount /user/uti/wordcount/input /user/uti/wordcount/out
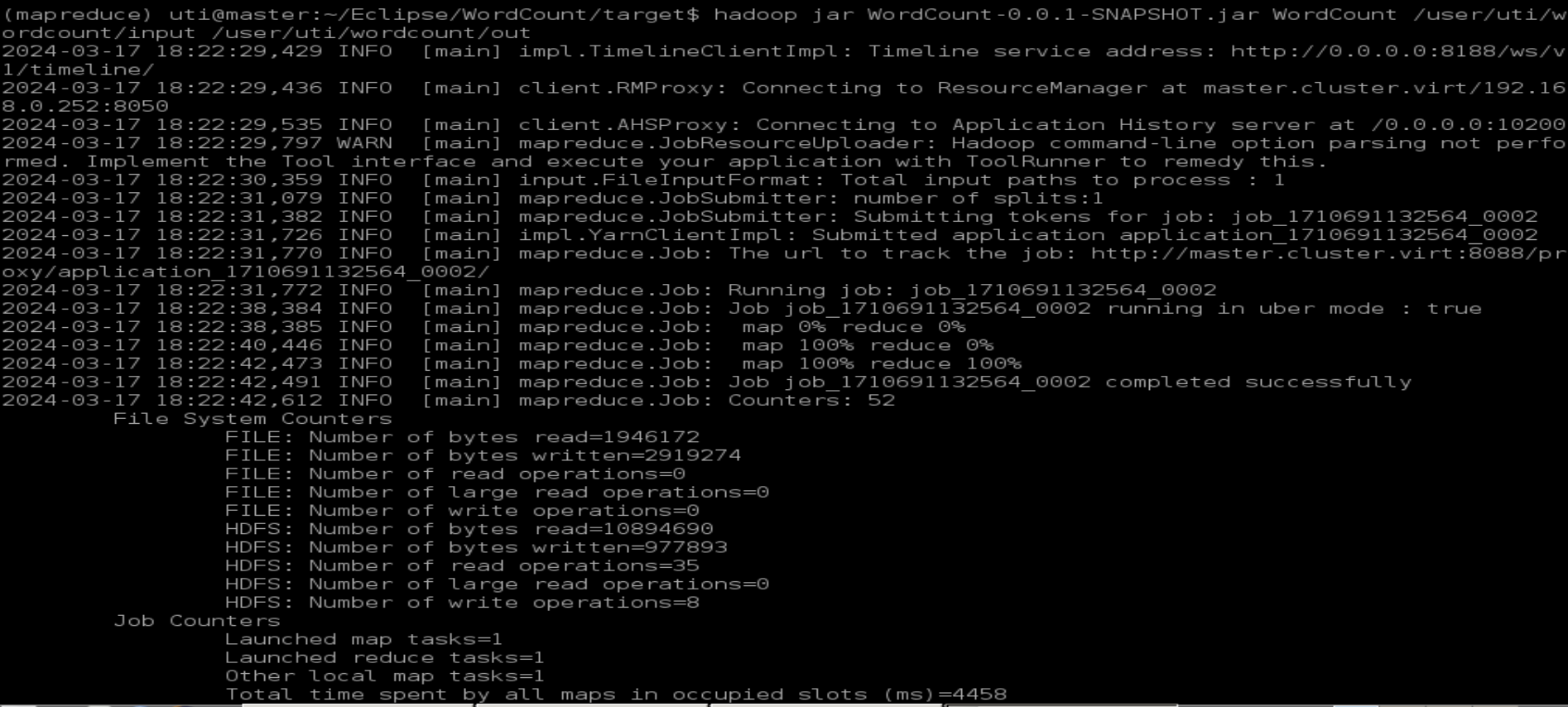
Afficher le résultat
hdfs dfs -cat wordcount/out/part*
Surveiller les jobs¶
Pour afficher les jobs MapReduce de la session en cours, visiter la page http://localhost:8088
Quand le programme MapReduce de l'exercice précédent est terminé, il est indiqué dans la capture suivante :
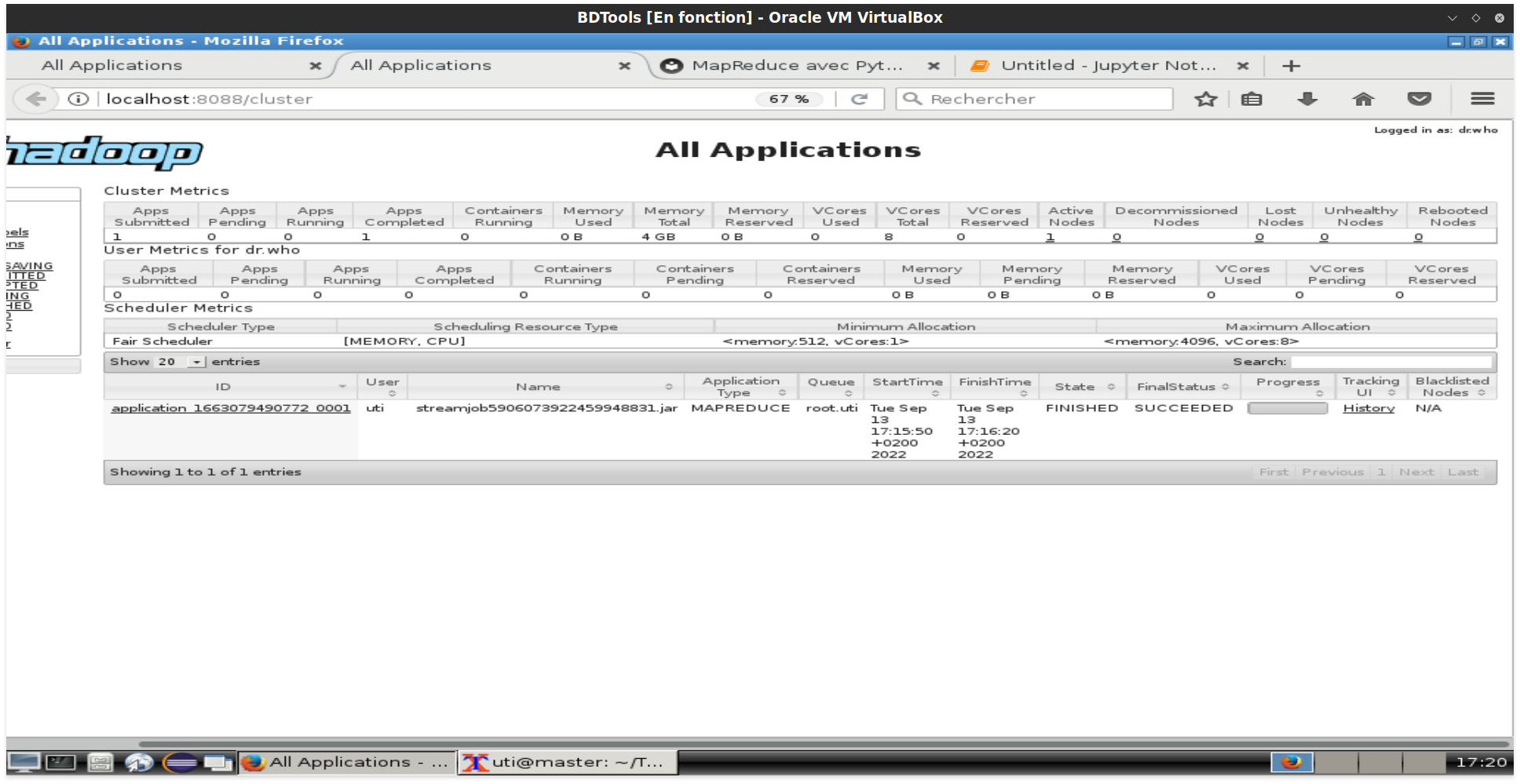
Pour afficher l'historique complet c'est à partir d'ici : http://localhost:8081
Il est aussi possible d'utiliser les commandes yarn :
- Pour afficher toutes les applications :
yarn application -list -appStates ALL - Pour arrêter une application :
yarn application -kill <id>
Exercices¶
Exercice 1  ¶
¶
- Transformer l'exemple WordCount afin d'obtenir le résultat trié dans l'ordre croissant du nombre d'occurrences. (Hint : exploiter la phase sort and shuffle qui trie la clé selon l'ordre alphabétique).
- Transformer le programme pour inverser l'ordre de tri.
Exercice 2 ¶
Sur les données de la production pétrolière de la section précédente et en utilisant MapReduce :
- Calculer la production annuelle de chaque champ.
- Trouver le champ avec la plus grande production par mois.
Exercice 3 ¶
On souhaite afficher pour les utilisateurs d’un réseau social le nombre d’amis en commun avec un autre utilisateur quand il visite la page de ce dernier.
Écrire un programme Map Reduce qui calcule le nombre d’amis en communs pour chaque paire d’utilisateurs sachant qu’on dispose d’un fichier contenant les identifiants des utilisateurs suivis des identifiants de leurs amis.
Le format de chaque ligne de ce fichier est :
Id_utilisateur : id_ami1, id_ami2, ….
Exemple : (réseau social contenant 5 utilisateurs)
10:20,30,40
20:10,30,40
30:10,20,40,50
40:10,20,30,50
50:30,40
 Idée :
Idée :
L’idée consiste à :
- Générer les couples d’amis à partir de chaque ligne (dans l’ordre croissant des clés couple 10-30 au lieu du couple 30-10 par exemple) : La ligne « 10:20,30,40 » génère ainsi : 10-20:20,30,40 10-30:20,30,40 10-40:20,30,40
- Regrouper les couples (même couleur) puis garder les éléments communs des 2 listes (remarquer que chaque couple apparaît exactement 2 fois). 10-20:20,30,40 10-20:10,30,40 10-20:30,40
Exercice 4 ¶
En utilisant la source json (books.json ), écrire un programme MapReduce qui calcule le nombre de livres pour chaque auteur.