
Pig¶
Premier exemple : Wordcount¶
Nous reprenons l'exemple de comptage de mots utilisé dans l'atelier MapReduce pour le résoudre avec le langage Pig Latin.
Structure d'un script Pig
Un script Pig comporte 3 phases :
1. Le chargement des données avec LOAD
2. Une série de transformations
3. L'affichage ou la sauvegarde des résultats
 Lancer la machine virtuelle et accéder à Pig en mode interactif à partir du terminal
Lancer la machine virtuelle et accéder à Pig en mode interactif à partir du terminal
pig -x mapreduce
grunt>
 Charger le fichier
Charger le fichier shakespeare.txt
lines = LOAD './shakespeare.txt' AS (line: chararray);
 Décomposer chaque ligne en mots
Décomposer chaque ligne en mots
words = FOREACH lines GENERATE FLATTEN(TOKENIZE(line)) AS word;
 Créer un groupe pour chaque mot
Créer un groupe pour chaque mot
word_groups = GROUP words BY word;
 Compter les éléments de chaque groupe
Compter les éléments de chaque groupe
word_count = FOREACH word_groups GENERATE COUNT(words) AS count, group;
 Trier par le nombre d'occurences
Trier par le nombre d'occurences
ordered_word_count = ORDER word_count BY count DESC;
 Sauvegarder sur HDFS
Sauvegarder sur HDFS STORE ordered_word_count INTO './word_count_result';
Un dossier word_count_result est créé où des fichiers part-r-???? contiennent les nombres d'occurences associés aux mots du fichier.
 Afficher le résultat
Afficher le résultat
hadoop fs -cat word_count_result/part-r-* | more
Vous pouvez aussi utiliser l'interface web de HDFS pour afficher le résultat dans le dossier 'word_count_result'
Exécution d'un script¶
Pour exécuter l'exemple précédent :
Créer un fichier wordcount.pig avec un éditeur de texte (geany) avec le code suivant :
lines = LOAD './shakespeare.txt' AS (line: chararray);
words = FOREACH lines GENERATE FLATTEN(TOKENIZE(line)) AS word;
word_groups = GROUP words BY word;
word_count = FOREACH word_groups GENERATE COUNT(words) AS count, group;
ordered_word_count = ORDER word_count BY count DESC;
STORE ordered_word_count INTO './word_count_result';
pig -x mapreduce wordcount.pig
Mode local
Avant de lancer un script pig, il est recommandé de le tester en local. Ceci est possible avec la commande suivante :
pig -x local wordcount.pig
Attention : dans ce mode d'exécution les chemins sont interprétés dans le système local et non HDFS.
Instructions Pig par l'exemple¶
Préparer les données
- Créer un dossier demo :
mkdir ~/demo - Télécharger les fichiers csv dans /home/uti/demo :
- Envoyer les données sur HDFS
hadoop fs -put /home/uti/demo
Charger des données sans schéma à partir d'un fichier CSV avec ',' comme séparateur. Puis limiter le nombre de tuples à 10
e1 = LOAD '/user/uti/demo/employee.csv' USING PigStorage (',');
e1_sample = limit e1 10;
dump e1_sample;
Charger avec un schéma
emp = LOAD '/user/uti/demo/employee.csv' USING PigStorage (',')
as (eid:chararray,fname:chararray,lname:chararray,department:chararray);
emp_sample = limit emp 10;
dump emp_sample;
Projection
emp = LOAD '/user/uti/demo/employee.csv' USING PigStorage (',')
as (eid:chararray,fname:chararray,lname:chararray,department:chararray);
emp_proj = FOREACH emp GENERATE $1, lname;
emp_sample = limit emp_proj 10;
dump emp_sample;
Filtrage pour avoir les employés (sans doublons) ayant reçu un salaire compris entre 5000 et 7000
sal = LOAD '/user/uti/demo/salary.csv' USING PigStorage (',') as (salary_id:chararray,employ_id:chararray,payment:double,p_date:datetime);
above_5k_7k = DISTINCT (FILTER sal BY payment >= 5000 AND payment <= 7000);
emp_sample = limit above_5k_7k 10;
dump emp_sample;
Nombre d'employés par département et afficher les 3 plus grands départements
emp = LOAD '/user/uti/demo/employee.csv' USING PigStorage (',') as (eid:chararray,fname:chararray,lname:chararray,department:chararray);
emp_group_dep = group emp by department;
-- ou emp_group_dep = group emp by $3;
group_count = FOREACH emp_group_dep GENERATE group AS dep, COUNT(emp.eid) AS nb_emp;
nbemp_dep = ORDER group_count BY nb_emp DESC;
top_dep = limit nbemp_dep 3;
dump top_dep;
Jointure : trouver le nom du département de chaque employé
emp = LOAD '/user/uti/demo/employee.csv' USING PigStorage (',') as (emp_id:chararray,fname:chararray,lname:chararray,dept_id:chararray);
dep = LOAD '/user/uti/demo/department.csv' USING PigStorage (',') as (dept_id:chararray,dept_name:chararray);
dep_emp = LIMIT (FOREACH (JOIN emp by (dept_id), dep by (dept_id)) GENERATE fname, lname, dept_name) 3;
DUMP dep_emp;
Test et performances¶
DESCRIBE
Elle permet d'afficher le schéma d'une relation.
Exemple
grunt> lines = LOAD './shakespeare.txt' AS (line: chararray);
grunt> words = FOREACH lines GENERATE FLATTEN(TOKENIZE(line)) AS word;
grunt> word_groups = GROUP words BY word;
grunt> word_count = FOREACH word_groups GENERATE COUNT(words) AS count, group;
grunt> DESCRIBE lines;
lines: {line: chararray}
grunt> DECRIBE word_groups;
word_groups: {group: chararray,words: {word: chararray}}
grunt> DESCRIBEvword_count;
word_count: {count: long,group: chararray}
Cette commande Pig permet de montrer les différentes transformations effectuées sur les données.
ILLUSTRATE relation|-script <nom_script>
Exemple : (source http://pig.apache.org)
grunt> cat visits.txt
Amy yahoo.com 19990421
Fred harvard.edu 19991104
Amy cnn.com 20070218
Frank nba.com 20070305
Fred berkeley.edu 20071204
Fred stanford.edu 20071206
grunt> cat visits.pig
visits = LOAD 'visits.txt' AS (user, url, timestamp);
recent_visits = FILTER visits BY timestamp >= '20071201';
historical_visits = FILTER visits BY timestamp <= '20000101';
DUMP recent_visits;
DUMP historical_visits;
STORE recent_visits INTO 'recent';
STORE historical_visits INTO 'historical';
grunt> exec visits.pig
(Fred,berkeley.edu,20071204)
(Fred,stanford.edu,20071206)
(Amy,yahoo.com,19990421)
(Fred,harvard.edu,19991104)
grunt> illustrate -script visits.pig
------------------------------------------------------------------------
| visits | user: bytearray | url: bytearray | timestamp: bytearray |
------------------------------------------------------------------------
| | Amy | yahoo.com | 19990421 |
| | Fred | stanford.edu | 20071206 |
------------------------------------------------------------------------
-------------------------------------------------------------------------------
| recent_visits | user: bytearray | url: bytearray | timestamp: bytearray |
-------------------------------------------------------------------------------
| | Fred | stanford.edu | 20071206 |
-------------------------------------------------------------------------------
---------------------------------------------------------------------------------------
| Store : recent_visits | user: bytearray | url: bytearray | timestamp: bytearray |
---------------------------------------------------------------------------------------
| | Fred | stanford.edu | 20071206 |
---------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------
| historical_visits | user: bytearray | url: bytearray | timestamp: bytearray |
-----------------------------------------------------------------------------------
| | Amy | yahoo.com | 19990421 |
-----------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
| Store : historical_visits | user: bytearray | url: bytearray | timestamp: bytearray |
-------------------------------------------------------------------------------------------
| | Amy | yahoo.com | 19990421 |
-------------------------------------------------------------------------------------------
Affiche les plans d'exécution logique, physique et les phases MapReduce.
EXPLAIN relation|-script <nom_script> [-out chemin] [-dot|-xml]
Exemple
grunt> EXPLAIN -script wordcount.pig -out explain_wordcount.txt
Le fichier explain_wordcount.txt obtenu contient :
#-----------------------------------------------
# New Logical Plan:
#-----------------------------------------------
ordered_word_count: (Name: LOStore Schema: count#112:long,group#109:chararray)
|
|---ordered_word_count: (Name: LOSort Schema: count#112:long,group#109:chararray)
| |
| count:(Name: Project Type: long Uid: 112 Input: 0 Column: 0)
|
|---word_count: (Name: LOForEach Schema: count#112:long,group#109:chararray)
| |
| (Name: LOGenerate[false,false] Schema: count#112:long,group#109:chararray)ColumnPrune:OutputUids=[112, 109]ColumnPrune:InputUids=[109, 110]
| | |
| | (Name: UserFunc(org.apache.pig.builtin.COUNT) Type: long Uid: 112)
| | |
| | |---words:(Name: Project Type: bag Uid: 110 Input: 0 Column: (*))
| | |
| | group:(Name: Project Type: chararray Uid: 109 Input: 1 Column: (*))
| |
| |---words: (Name: LOInnerLoad[1] Schema: word#109:chararray)
| |
| |---(Name: LOInnerLoad[0] Schema: group#109:chararray)
|
|---word_groups: (Name: LOCogroup Schema: group#109:chararray,words#110:bag{#114:tuple(word#109:chararray)})
| |
| word:(Name: Project Type: chararray Uid: 109 Input: 0 Column: 0)
|
|---words: (Name: LOForEach Schema: word#118:chararray)
| |
| (Name: LOGenerate[true] Schema: word#118:chararray)
| | |
| | (Name: UserFunc(org.apache.pig.builtin.TOKENIZE) Type: bag Uid: 116)
| | |
| | |---(Name: Cast Type: chararray Uid: 98)
| | |
| | |---line:(Name: Project Type: bytearray Uid: 98 Input: 0 Column: (*))
| |
| |---(Name: LOInnerLoad[0] Schema: line#98:bytearray)
|
|---lines: (Name: LOLoad Schema: line#98:bytearray)RequiredFields:null
#-----------------------------------------------
# Physical Plan:
#-----------------------------------------------
ordered_word_count: Store(hdfs://master.cluster.virt:8020/user/uti/word_count_result:org.apache.pig.builtin.PigStorage) - scope-18
|
|---ordered_word_count: POSort[bag]() - scope-17
| |
| Project[long][0] - scope-16
|
|---word_count: New For Each(false,false)[bag] - scope-15
| |
| POUserFunc(org.apache.pig.builtin.COUNT)[long] - scope-11
| |
| |---Project[bag][1] - scope-10
| |
| Project[chararray][0] - scope-13
|
|---word_groups: Package(Packager)[tuple]{chararray} - scope-7
|
|---word_groups: Global Rearrange[tuple] - scope-6
|
|---word_groups: Local Rearrange[tuple]{chararray}(false) - scope-8
| |
| Project[chararray][0] - scope-9
|
|---words: New For Each(true)[bag] - scope-5
| |
| POUserFunc(org.apache.pig.builtin.TOKENIZE)[bag] - scope-3
| |
| |---Cast[chararray] - scope-2
| |
| |---Project[bytearray][0] - scope-1
|
|---lines: Load(hdfs://master.cluster.virt:8020/user/uti/shakespeare.txt:org.apache.pig.builtin.PigStorage) - scope-0
#--------------------------------------------------
# Map Reduce Plan
#--------------------------------------------------
MapReduce node scope-19
Map Plan
word_groups: Local Rearrange[tuple]{chararray}(false) - scope-53
| |
| Project[chararray][0] - scope-55
|
|---word_count: New For Each(false,false)[bag] - scope-42
| |
| Project[chararray][0] - scope-43
| |
| POUserFunc(org.apache.pig.builtin.COUNT$Initial)[tuple] - scope-44
| |
| |---Project[bag][1] - scope-45
|
|---Pre Combiner Local Rearrange[tuple]{Unknown} - scope-56
|
|---words: New For Each(true)[bag] - scope-5
| |
| POUserFunc(org.apache.pig.builtin.TOKENIZE)[bag] - scope-3
| |
| |---Cast[chararray] - scope-2
| |
| |---Project[bytearray][0] - scope-1
|
|---lines: Load(hdfs://master.cluster.virt:8020/user/uti/shakespeare.txt:org.apache.pig.builtin.PigStorage) - scope-0--------
Combine Plan
word_groups: Local Rearrange[tuple]{chararray}(false) - scope-57
| |
| Project[chararray][0] - scope-59
|
|---word_count: New For Each(false,false)[bag] - scope-46
| |
| Project[chararray][0] - scope-47
| |
| POUserFunc(org.apache.pig.builtin.COUNT$Intermediate)[tuple] - scope-48
| |
| |---Project[bag][1] - scope-49
|
|---word_groups: Package(CombinerPackager)[tuple]{chararray} - scope-52--------
Reduce Plan
Store(hdfs://master.cluster.virt:8020/tmp/temp-483208883/tmp-1292167423:org.apache.pig.impl.io.InterStorage) - scope-20
|
|---word_count: New For Each(false,false)[bag] - scope-15
| |
| POUserFunc(org.apache.pig.builtin.COUNT$Final)[long] - scope-11
| |
| |---Project[bag][1] - scope-50
| |
| Project[chararray][0] - scope-13
|
|---word_groups: Package(CombinerPackager)[tuple]{chararray} - scope-7--------
Global sort: false
----------------
MapReduce node scope-22
Map Plan
ordered_word_count: Local Rearrange[tuple]{tuple}(false) - scope-26
| |
| Constant(all) - scope-25
|
|---New For Each(false)[tuple] - scope-24
| |
| Project[long][0] - scope-23
|
|---Load(hdfs://master.cluster.virt:8020/tmp/temp-483208883/tmp-1292167423:org.apache.pig.impl.builtin.RandomSampleLoader('org.apache.pig.impl.io.InterStorage','100')) - scope-21--------
Reduce Plan
Store(hdfs://master.cluster.virt:8020/tmp/temp-483208883/tmp569443691:org.apache.pig.impl.io.InterStorage) - scope-35
|
|---New For Each(false)[tuple] - scope-34
| |
| POUserFunc(org.apache.pig.impl.builtin.FindQuantiles)[tuple] - scope-33
| |
| |---Project[tuple][*] - scope-32
|
|---New For Each(false,false)[tuple] - scope-31
| |
| Constant(-1) - scope-30
| |
| Project[bag][1] - scope-28
|
|---Package(Packager)[tuple]{chararray} - scope-27--------
Global sort: false
Secondary sort: true
----------------
MapReduce node scope-37
Map Plan
ordered_word_count: Local Rearrange[tuple]{long}(false) - scope-38
| |
| Project[long][0] - scope-16
|
|---Load(hdfs://master.cluster.virt:8020/tmp/temp-483208883/tmp-1292167423:org.apache.pig.impl.io.InterStorage) - scope-36--------
Reduce Plan
ordered_word_count: Store(hdfs://master.cluster.virt:8020/user/uti/word_count_result:org.apache.pig.builtin.PigStorage) - scope-18
|
|---New For Each(true)[tuple] - scope-41
| |
| Project[bag][1] - scope-40
|
|---Package(LitePackager)[tuple]{long} - scope-39--------
Global sort: true
Quantile file: hdfs://master.cluster.virt:8020/tmp/temp-483208883/tmp569443691
----------------
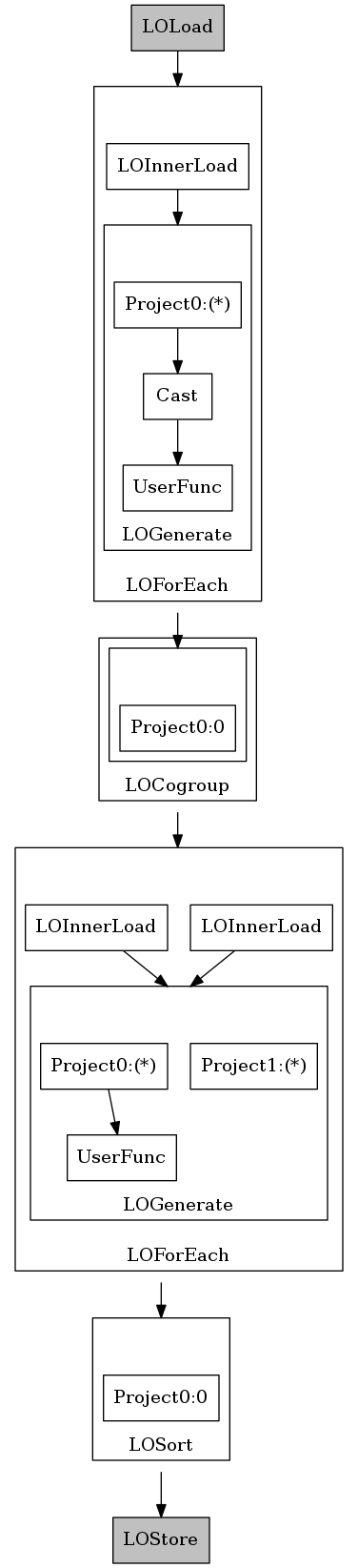
Pour avoir un graphe d'exécution :
grunt> EXPLAIN -script wordcount.pig -out explain_wordcount.dot -dot
Puis convertir le fichier .dot en png :
apt install graphviz -y
dot -Tpng -out explain_wordcount.png explain_wordcount.dot
Ce qui donne :
Références Pig Latin¶
Pour une référence complète du langage Pig Latin, aller sur la page de documentation (ici)
Voici aussi, un mémo du langage :
Exercice  ¶
¶
Datasets¶
Ci-après la description des données sur les crédits offerts par une banque à ses clients. (source : https://www.kaggle.com ) Le fichier credit_risk_dataset.csv est structuré ainsi :
person_age : âge du client
person_income : revenu annuel du client
person_home_ownership : propriété de la maison : OWN, RENT, MORTGAGE
person_emp_length : durée en mois du crédit
loan_intent : motif du crédit (MEDICAL, EDUCATION, PERSONAL, ...)
loan_grade : A, B, C, D
loan_amnt : montant du crédit
loan_int_rate : taux d'intérêt
loan_status : état du crédit (1: non remboursé, 0: remboursé)
loan_percent_income : pourcentage du montant du crédit par rapport au revenu
cb_person_default_on_file : Y/N
cb_person_cred_hist_length :historique (nombre de crédits)
Travail à faire¶
Répondre aux questions suivantes avec Pig.
- Calculer le montant total et la durée moyenne des crédits non remboursés.
- Calculer le pourcentage des crédits remboursés et non remboursés.
- Quelle est la distribution des différents états de propriété de la maison.
- Quels sont les 3 motifs de crédits les plus demandés.
- Calculer le pourcentage des crédits remboursés et non remboursés par motif puis par grade.