Cas Pratique : Data Pipeline avec Pig et Hive¶
Introduction¶
Les données Clickstream constitue l'ensembles des informations qu'un utilisateur laisse lors de la visite d'un site web.
Ces données sont capturées généralement par le serveur web et enregistrées dans des fichiers semi-structurés appelés logs.
Ces logs contiennent des informations comme l'adresse IP, le navigateur web, la date, le système d'exploitation, etc.
Le travail consiste à automatiser les tâche d'ingestion, de nettoyage, de transformation des données pour générer des données exploitables dans la phase d'analyse.
Sources de données et Pipeline¶
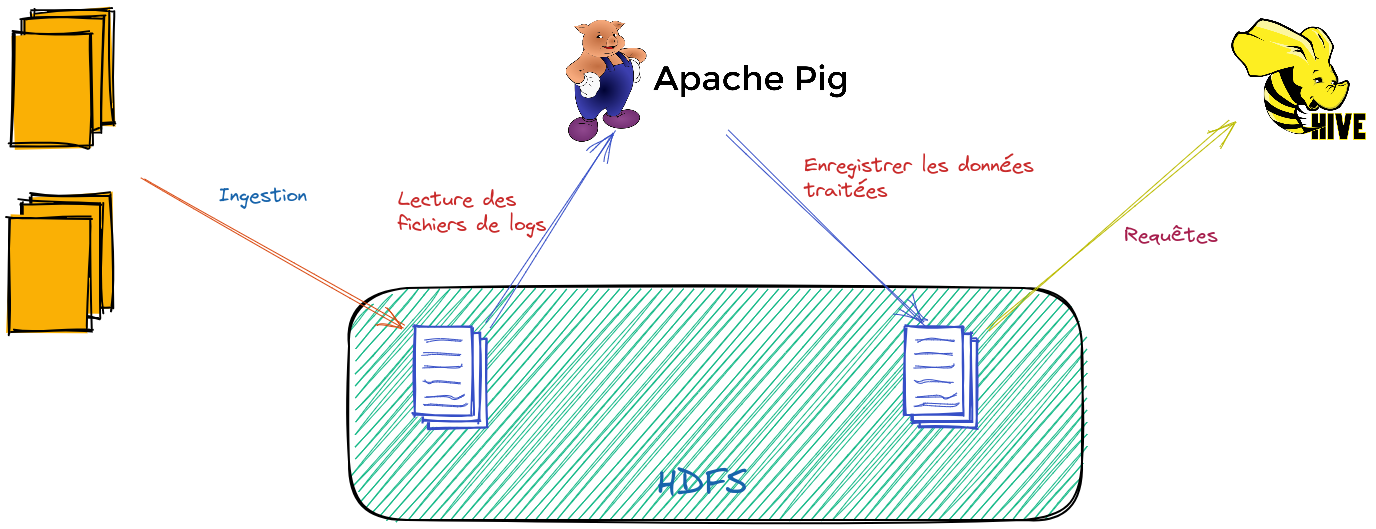
Le pipeline souhaité est représenté par la figure suivante :
Les fichiers sources sont regroupés dans cette archive :
- products.tsv : Format TSV avec entête et 2 colonnes (url, category)
- users.tsv : Format TSV avec entête et 3 colonnes (SWID, BIRTH_DT, GENDER_CD)
- log.tsv : Format TSV sans entête et 179 colonnes
load_files.pig
Télécharger le script load_files.pig qui permet de parser ces fichiers.
Travail demandé¶
- Ajouter les transformations nécessaires avec Pig pour obtenir la structure suivante : (user_id, age, gender, country, state, city, logdate, ip, product_category, url)
- Répondre aux questions (avec Hive) :
- Le top 5 des produits visités par coordonnées géographiques de l'utilisateur.
- Le nombre de sessions par coordonnées géographiques.
- Le nombre de sessions par genre, produit et coordonnées géographiques.