
Premiers pas avec Cypher¶
Base de données exemple : Movie Graph¶
Noeuds et relations¶
C'est une BD graphe disponible avec Neo4j pour apprendre Cypher. Elle modélise les relations entre 2 noeuds :
- Person : représentant une personne et peut être un acteur, réalisateur, produteur ou un spectateur
- Movie : un film
Les relations possibles entre ces noeuds sont présentées dans le graphe ci-dessous.

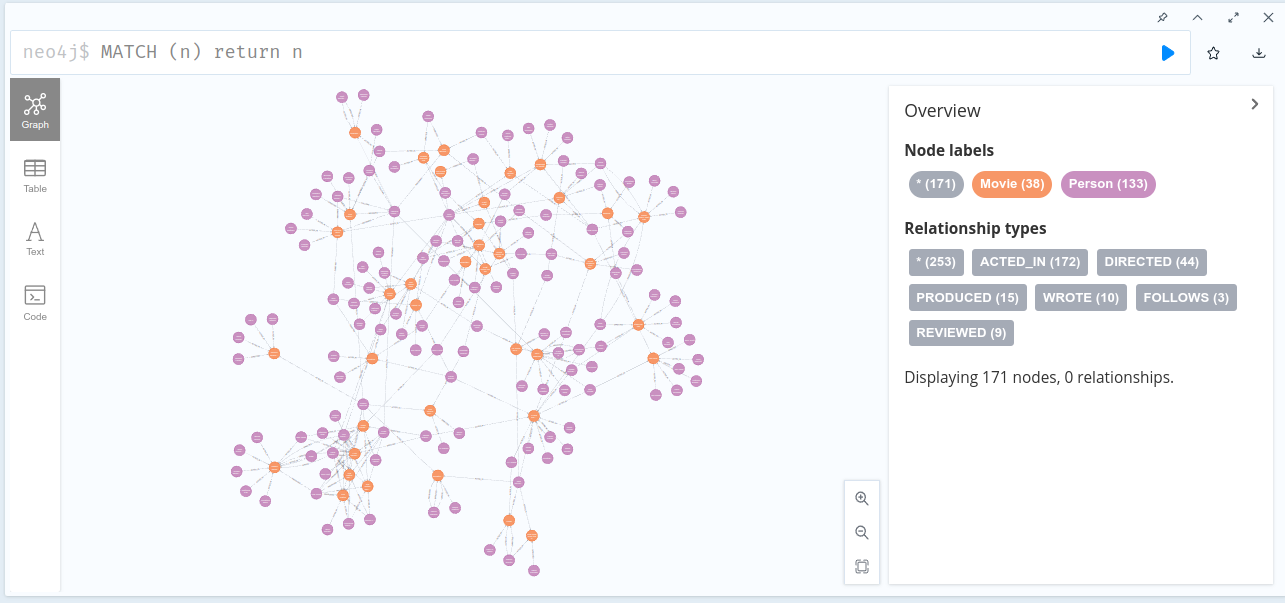
Ce graphe comporte 133 noeuds de type Person et 38 Movie.
Propriétés¶
Les noeuds Movie possède les propriétés :
- title : le titre du film qui est aussi son identifiant.
- tagline : résumé du film.
- released : date de parution du film.
Les noeuds Person possède les propriétés :
- name : le nom de la personne qui est aussi son identifiant.
- born : année de naissabce.
Les différentes relations possèdent aussi des propriétés :
| Relation | Propriétés |
|---|---|
| ACTED_IN | propriété roles (liste des rôles d'un acteur dans un film) |
| DIRECTED | ... |
| PRODUCED | ... |
| WROTE | ... |
| REVIEWED | propriétés rating (évaluation) et summary (un commentaire) |
Créer la base de données¶
Version Enterprise
La manipulation de plusieurs bases de données n'est supporté qu'avec la version Enterprise. Dans ce cas, avant de procéder aux opérations qui suivent commencer par :
- Créer une base de données "MovieGraph"
CREATE DATABASE MovieGraph - Basculer ver la nouvelle base de données
:use MovieGraph
 Démarrer le guide de la base Movie Graph à partir du shell Neo4j
Démarrer le guide de la base Movie Graph à partir du shell Neo4j
:guide movie-graph
 Cliquer sur Next puissur le bloc de code pour l'insérer dans le shell
Cliquer sur Next puissur le bloc de code pour l'insérer dans le shell
Le code est disponible dans le fichier movie-graph.cypher
 Exécuter le code
Exécuter le code
Vérifier le graphe complet
MATCH (n) RETURN n
Pattern Cypher¶
Le langage Cypher utilise des symboles spécifiques pour représenter les éléments du graphe dans ses requêtes.
Les neouds sont représentés par des parenthèses (). Pour désigner son type ou label on utilise : comme dans (:Person).
Les relation sont notées avec deux tirets reliant deux noeuds, par exemple : (:Person)--(:Movie).
La direction de la relation est indiquée avec > ou < , comme (:Person)→(:Movie) équivalent à (:Movie)←(:Person).
Le type de la relation peut être ajouté entre les tirets entre crochets , par exemple [:ACTED_IN].
Les propriétés des noeuds et des relations sont ajoutés dans un bloc JSON.
Des variables sont aussi ajoutées devant les labels comme (n:Person).
Pour des chemins de taille variable (n:Person)-[*]-(b:Person).
Pour des chemins de taille variable mais suivant un type de relation (n:Person)-[:ACTED*]-(b:Person).
Pour des chemins d'une taille spécifique (n:Person)-[*3..5]-(b:Person) (relation de niveau entre 3 et 5, la valeur 0 équivaut une absence de relation).
Exemple Cypher pattern
(m:Movie {title: 'Cloud Atlas'})<-[:ACTED_IN]-(p:Person)
Conventions
Voici quelques conventions à suivre avec Cypher :
- Un label commence par majuscule : Person
- Une relation est toute en majuscules : ACTED_IN
- Une propriété est en minuscule : birthDate
Lecture de données¶
L'équivalent de SELECT dans Cypher est la commande MATCH.
Syntaxe MATCH
MATCH patter_cypher
[WHERE <condition>]
RETURN <expression1>, ...
[SKIP <entier>]
[LIMIT <entier>]
[ORDER BY <champ> [DESC], ...]
Schéma de la BD
Visualiser le schéma de la base de données en cours permet de comprendre la structure du graphe de propriétés à manipuler avant de commencer à écrire des requêtes. Ce schéam peut être généré automatiquement avec la commande :
CALL db.schema.visualization
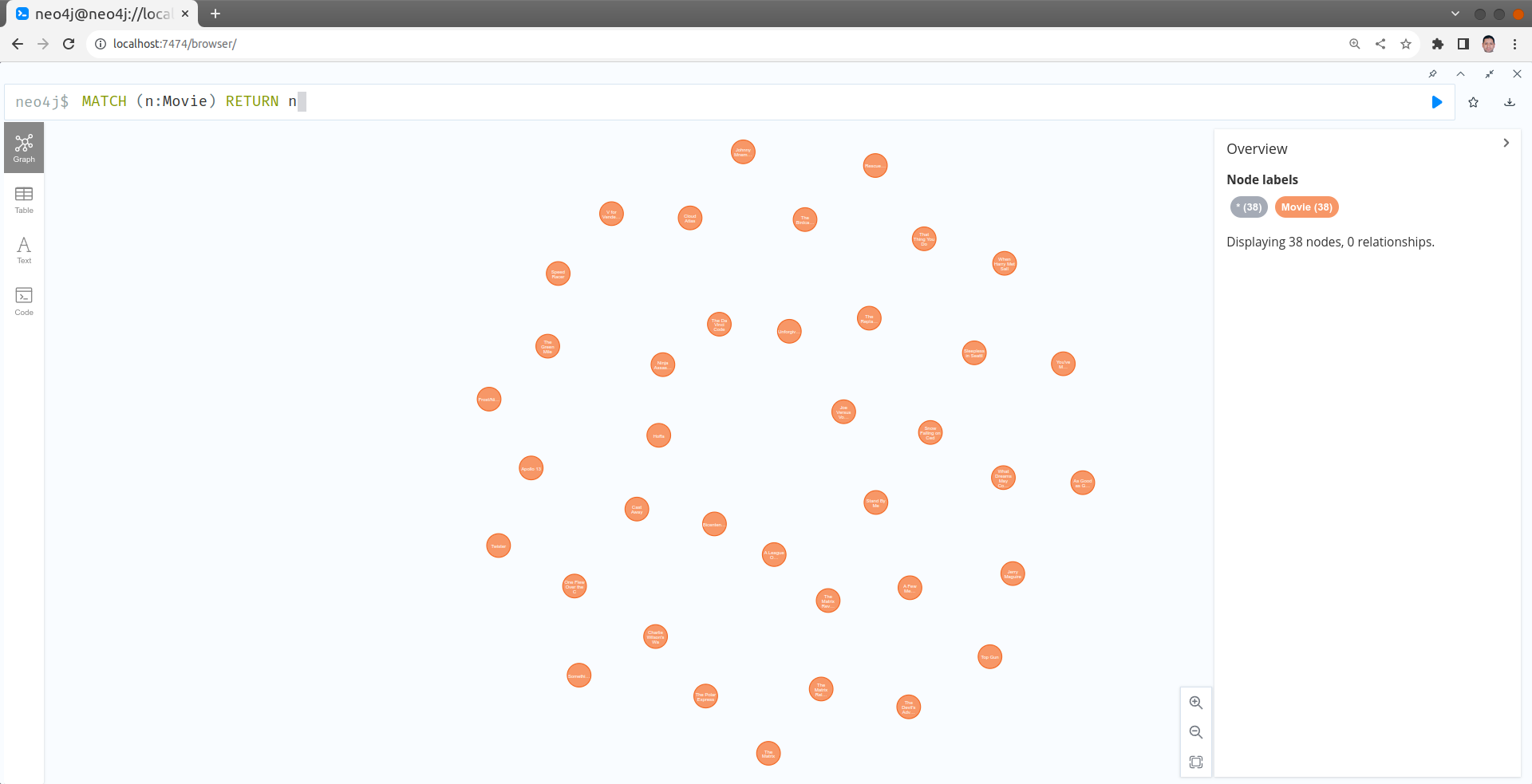
Trouver tous les films
MATCH (n:Movie) RETURN n
Trouver la date de sortie du film "The Matrix"
MATCH (n:Movie {title:'The Matrix'}) RETURN n.released as année
ou
MATCH (n:Movie) WHERE n.title='The Matrix' RETURN n.released as année
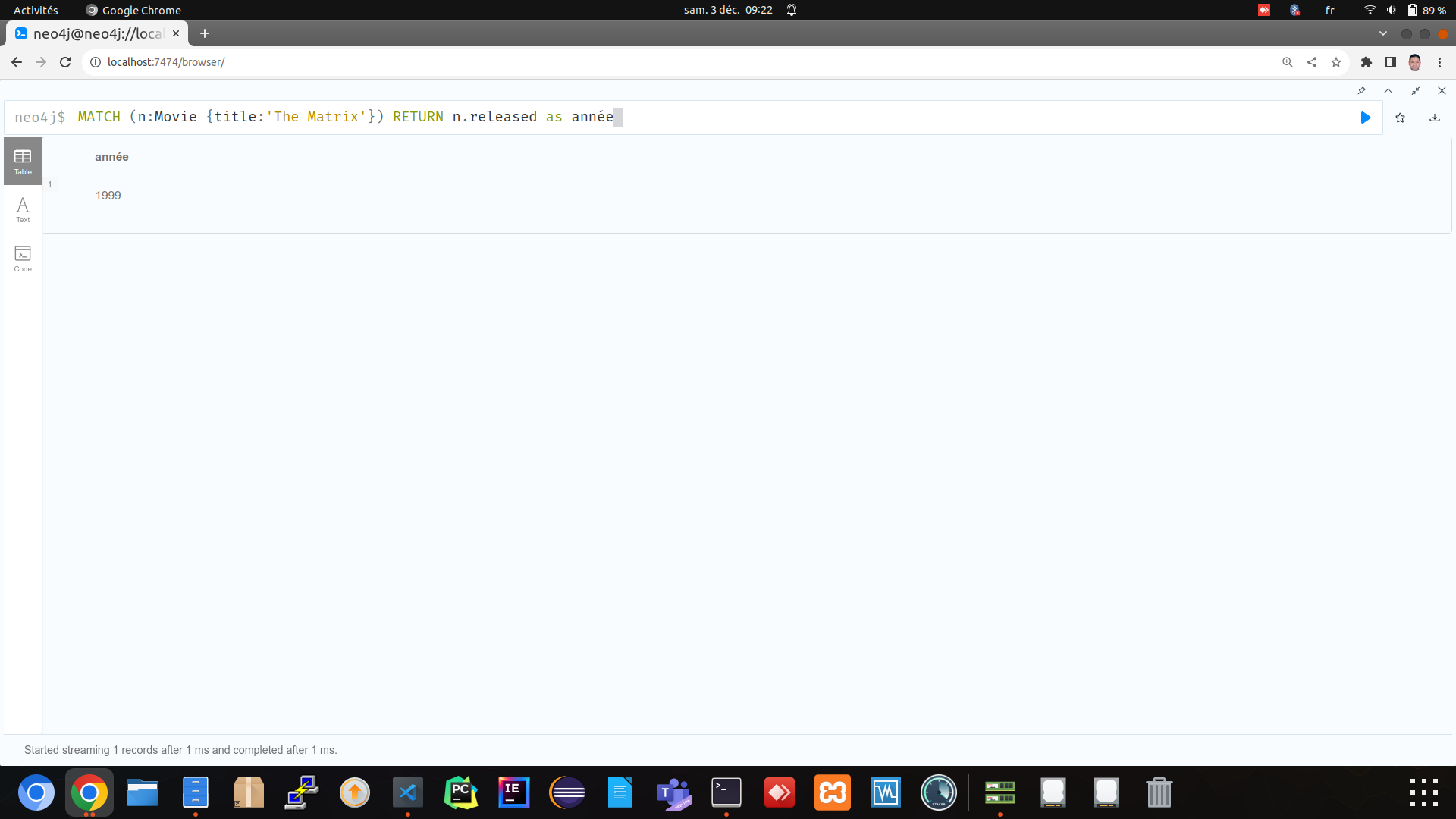
Trouver les films réalisés par "Clint Eastwood".
MATCH (m:Movie)<-[:DIRECTED]-(:Person {name:'Clint Eastwood'}) RETURN m
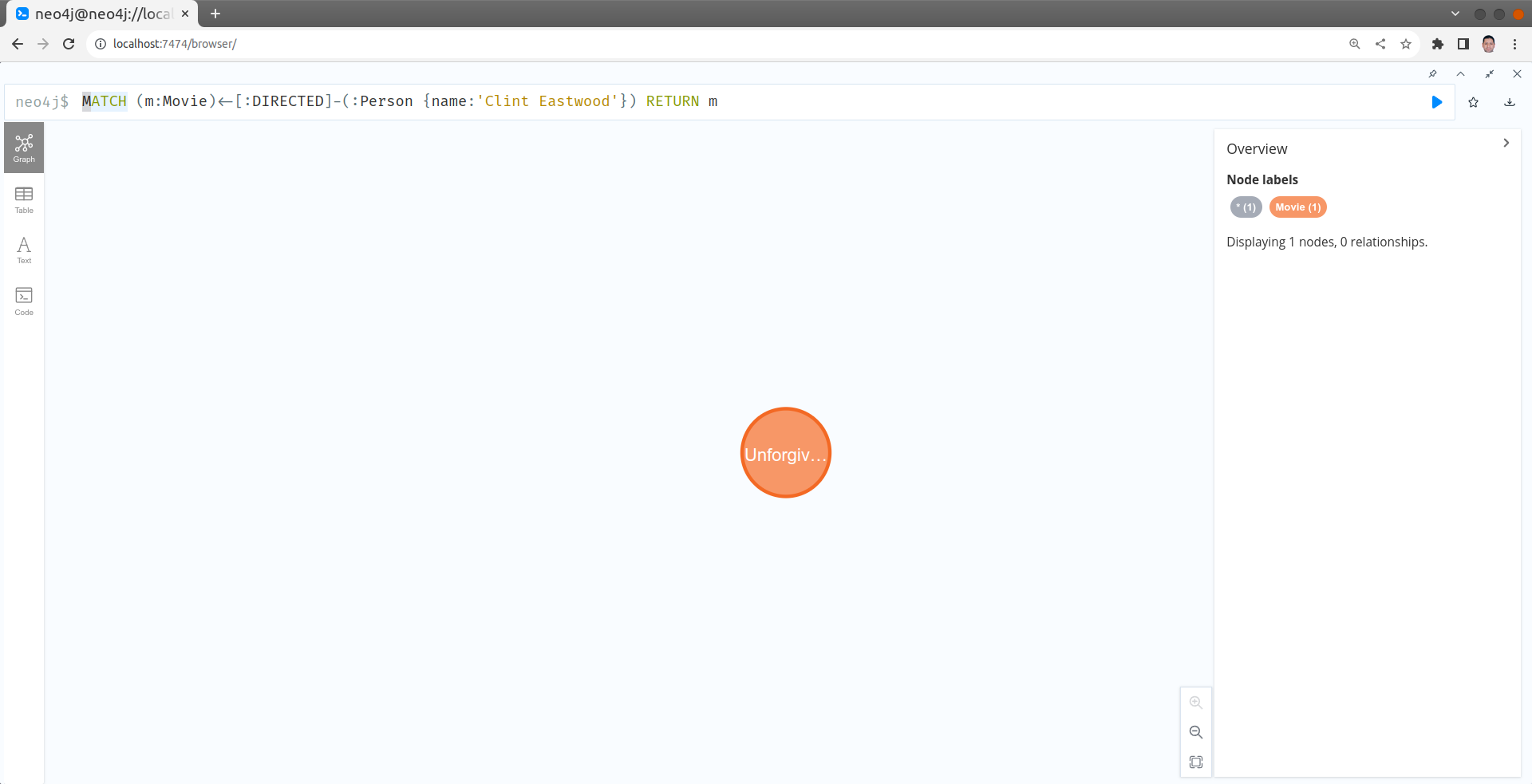
 Trouver 3 films sortis avant 2000
Trouver 3 films sortis avant 2000
MATCH (m:Movie) WHERE m.released<2000 RETURN m LIMIT 3
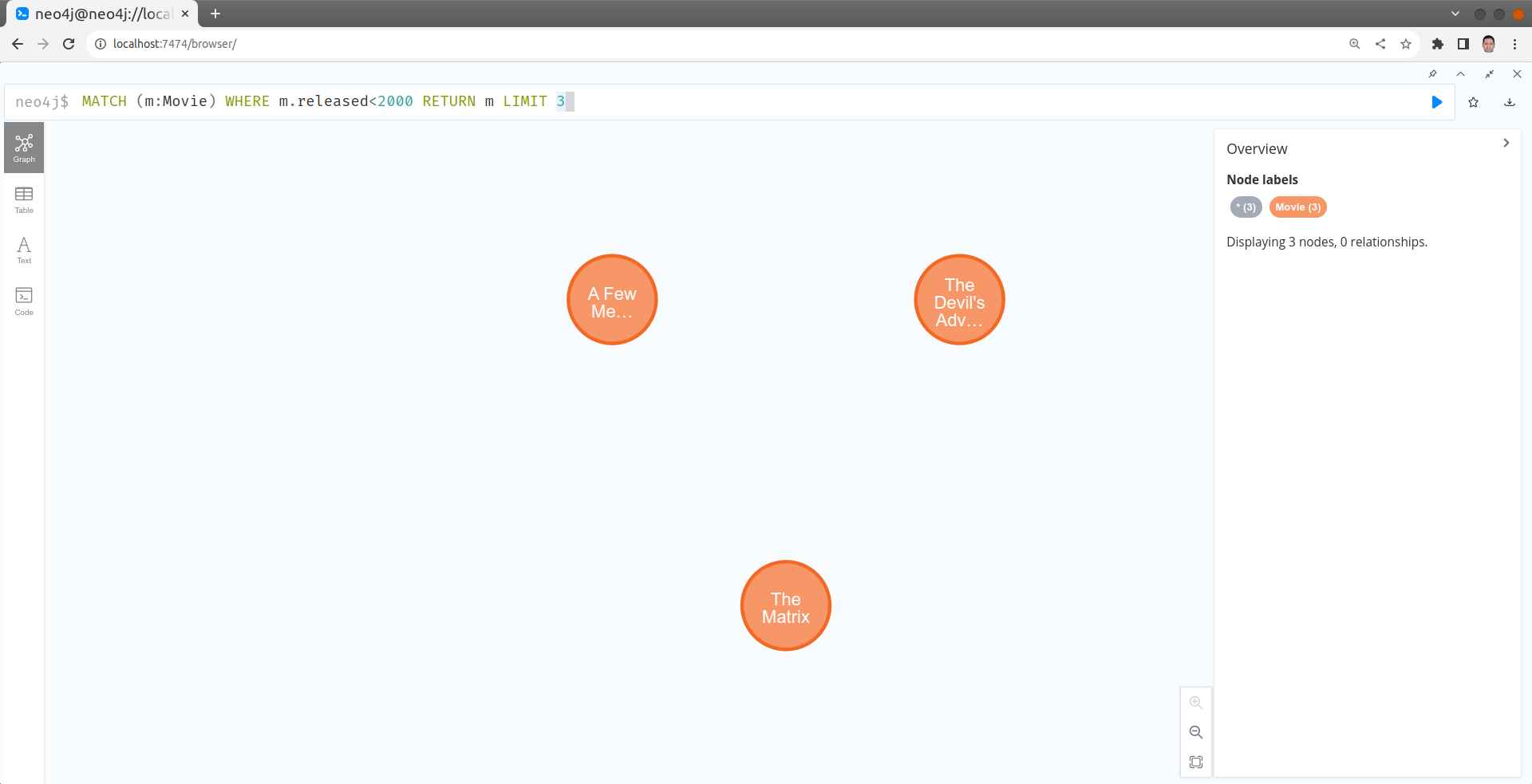
 Trouver les acteurs dont le prénom est "Michael"
Trouver les acteurs dont le prénom est "Michael"
MATCH (p:Person)-[:ACTED_IN]->()
WHERE toLower(p.name) STARTS WITH 'michael'
RETURN DISTINCT p.name
Cypher multi-ligne
Pour écrire du code Cypher sur plusieurs ligne, utiliser Shift+Enter pour retourner à la ligne. Dans ce cas, pour exécuter le bloc appuyer sur Ctrl+Enter.
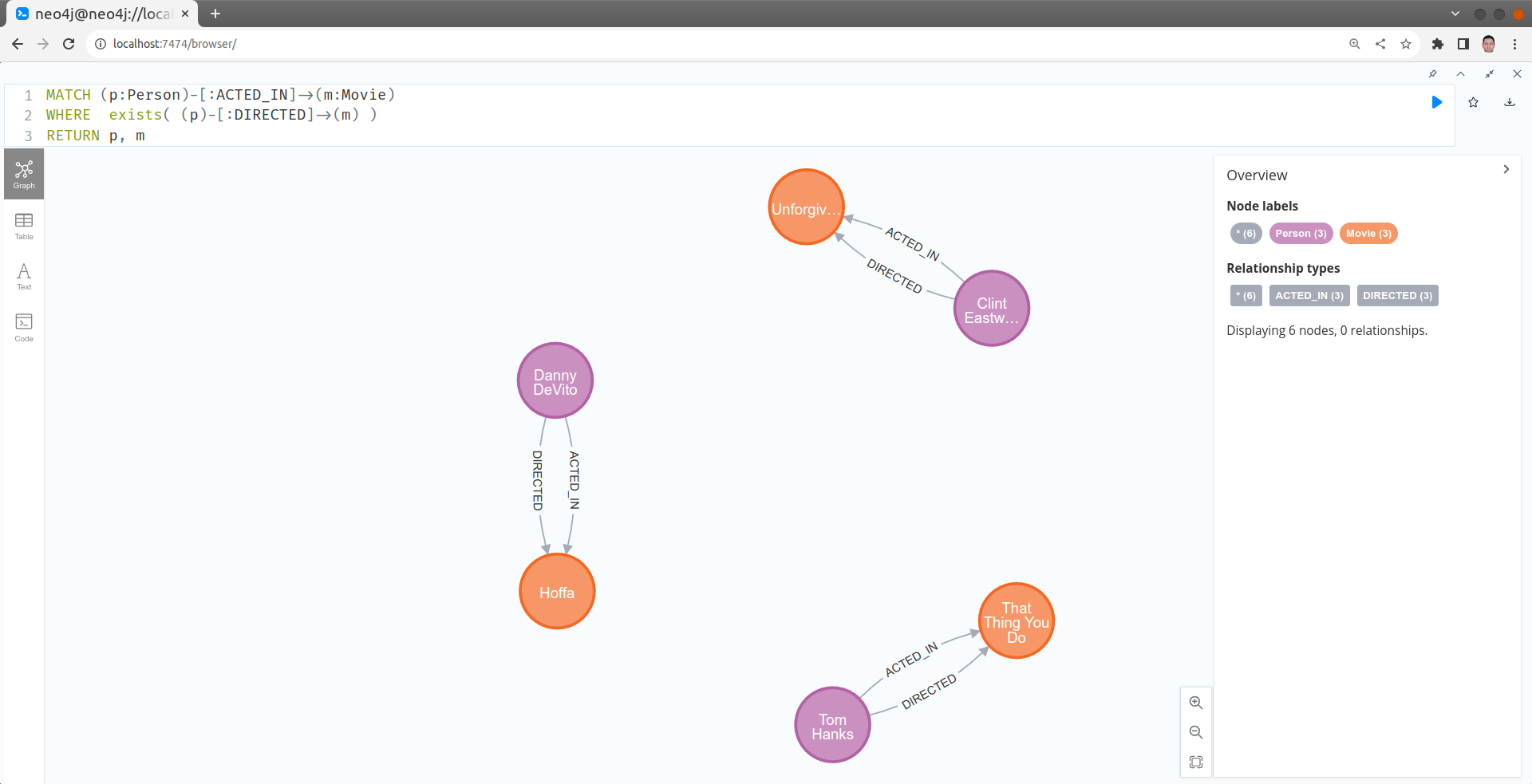
 Quels sont les réalisateurs qui ont aussi joué un rôle dans le même film qu'ils ont réalisé.
Quels sont les réalisateurs qui ont aussi joué un rôle dans le même film qu'ils ont réalisé.
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE exists( (p)-[:DIRECTED]->(m) )
RETURN p, m
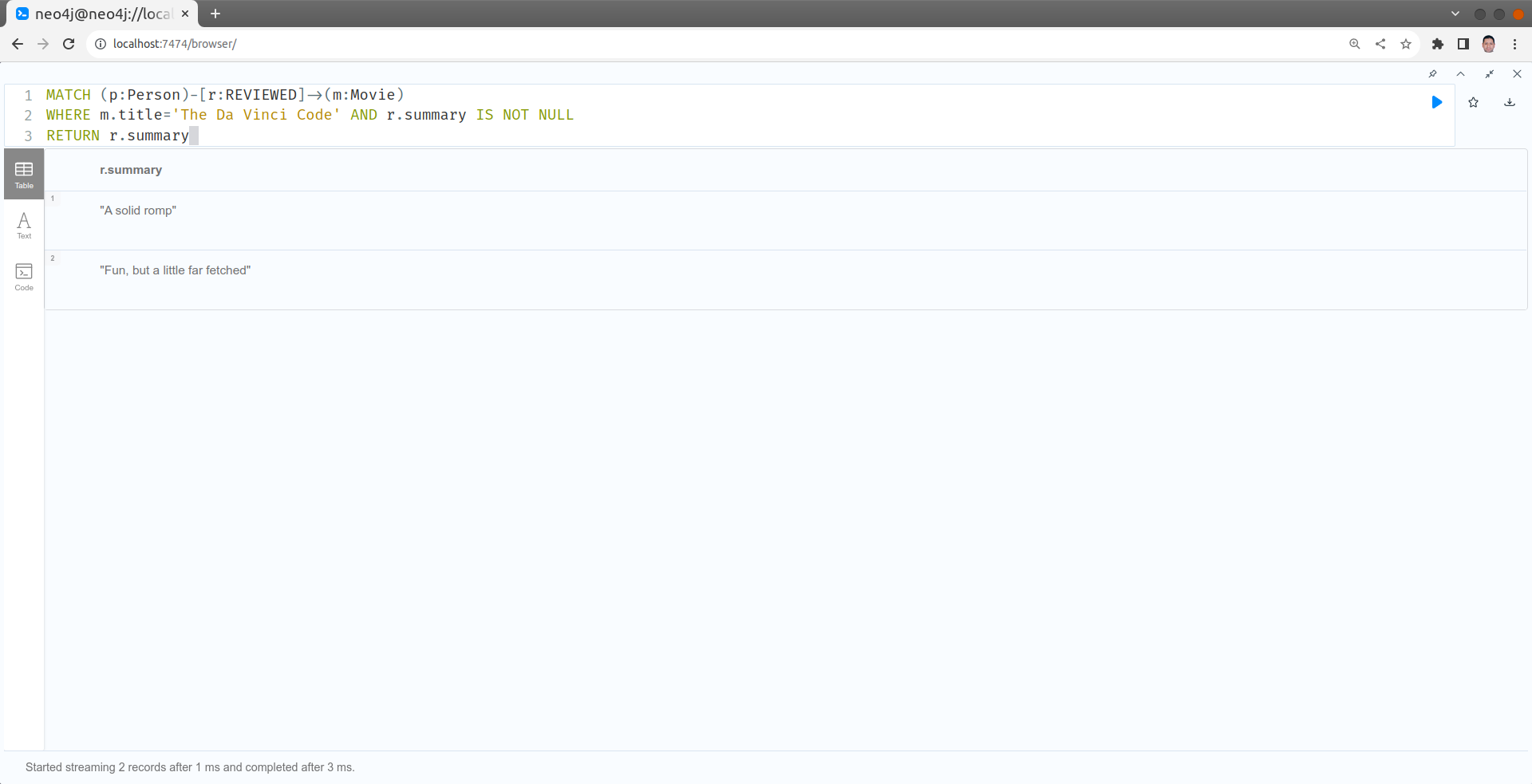
 Quels sont les commentaires laissés par les utilisateurs lors de l'évaluation du film "The Da Vinci Code".
Quels sont les commentaires laissés par les utilisateurs lors de l'évaluation du film "The Da Vinci Code".
MATCH (p:Person)-[r:REVIEWED]->(m:Movie)
WHERE m.title='The Da Vinci Code' AND r.summary IS NOT NULL
RETURN r.summary
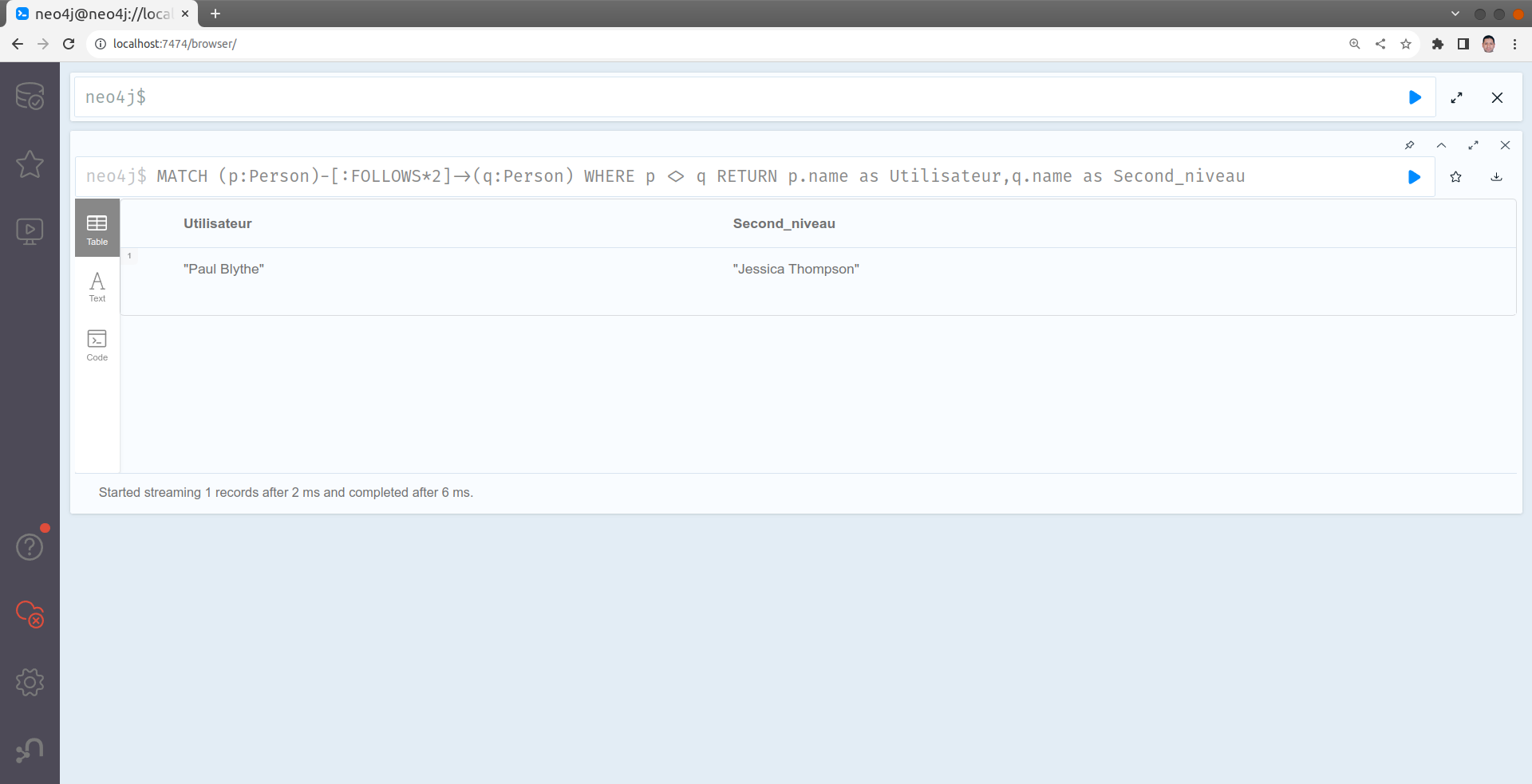
 Trouver les personnes qui suivies par les personnes qu'une personne suit (comme la relation amis de mes amis).
Trouver les personnes qui suivies par les personnes qu'une personne suit (comme la relation amis de mes amis).
MATCH (p:Person)-[:FOLLOWS*2]->(q:Person)
WHERE p <> q
RETURN p.name as Utilisateur,q.name as Second_niveau
Écriture de données¶
Insertion de noeuds¶
Pour créer des éléments de grpahe deux clauses sont utilisées par Cypher : CREATE et MERGE.
La différence entre ces clause est que MERGE requiert la saisie d'une valeur pour l'identifiant et évite d'avoir des doublons.
CREATE|MERGE <cypher_pattern>
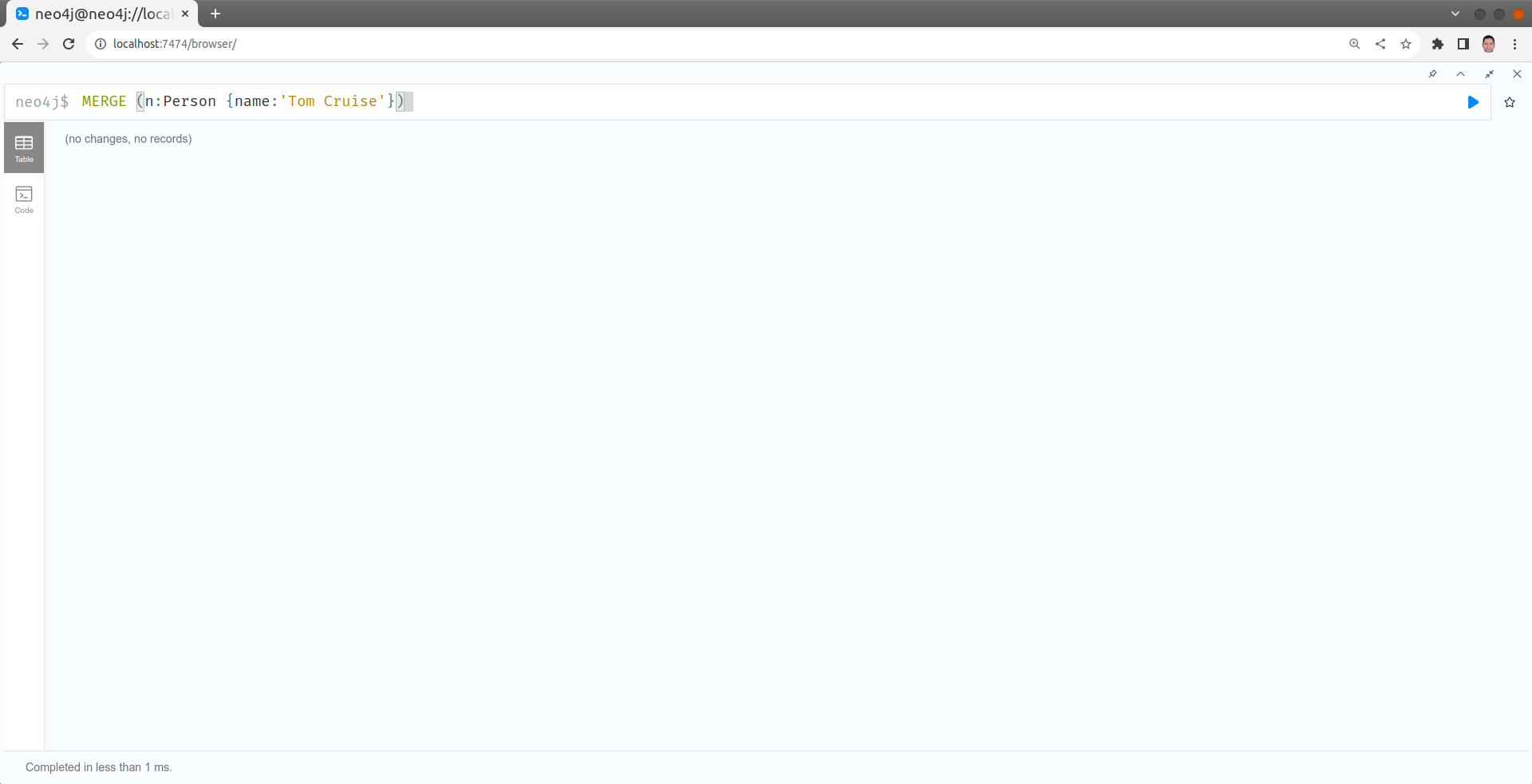
Créer un nouveau noeud Person
MERGE (:Person {name:'Tom Cruise'})
Aucun noeud créé, parce qu'il est déjà existant.
Créer une relation entre noeuds existants
"Angela Scope" a évalué le film "Cloud Atlas" et a donné un rating=95
MATCH (n:Person {name:'Angela Scopee'})
MATCH (m:Movie {title:'Cloud Atlas'})
MERGE (n)-[:REVIEWED {rating:95}]->(m)
Créer une structure
Ajouter un film 'Jurassic Park' sorti en 1993 et son réalisateur "Steven Spielberg".
MERGE (:Movie {title:'Jurassic Park', released:1993})<-[:DIRECTED]-(:Person {name:'Steven Spielberg'})
Mise à jour de noeuds¶
La clause MERGE sert aussi à mettre à jour les propriétés d'un noeud exitant. Il est possible de faire la mise à jour en associant MATCH et SET. Cette dernière permet de modifier la valeur d'un propriété existante ou définir une nouvelle propriété. Pour supprimer une propriété c'est REMOVE qui est utilisée.
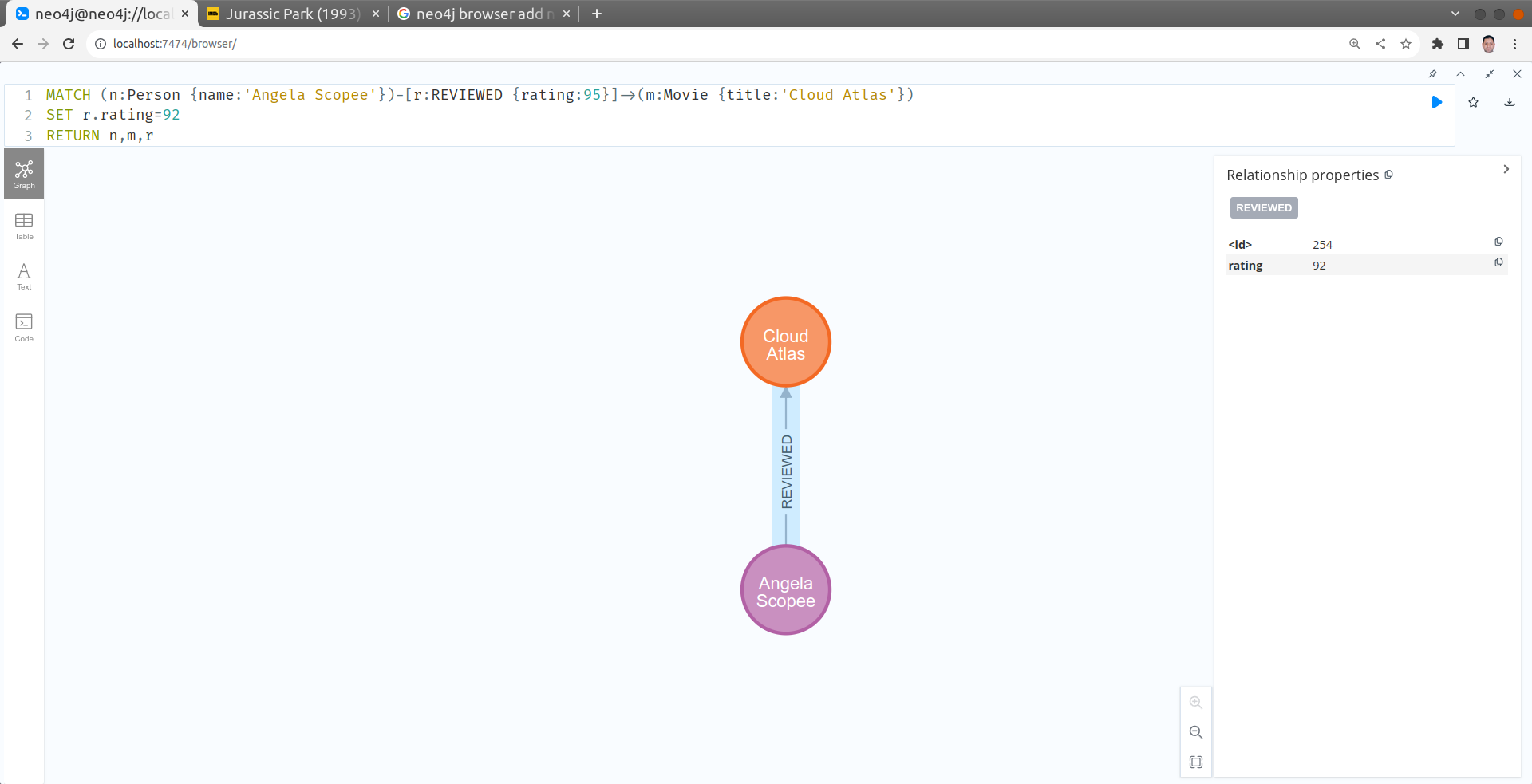
Modifier l'éavluation de "Angela Scope" du film "Cloud Atlas" en 92
MATCH (n:Person {name:'Angela Scopee'})-[r:REVIEWED {rating:95}]->(m:Movie {title:'Cloud Atlas'})
SET r.rating=92
RETURN n,m,r
Supprimer la propriété released du film 'Jurassic Park'.
MATCH (m:Movie) WHERE m.title='Jurassic Park'
REMOVE m.released
Effectuer une mise à jour selon le comportenent de MERGE
// Trouver ou créer une personne
MERGE (p:Person {name: 'McKenna Grace'})
// Ajouter cette propriété `createdAt` si la personne est créée
ON CREATE SET p.createdAt = datetime()
// Ajouter lanpropriété `updatedAt` si la personne existe et n a pas été créée
ON MATCH SET p.updatedAt = datetime()
// Dans tous les cas modifier la propriété `born`
SET p.born = 2006
RETURN p
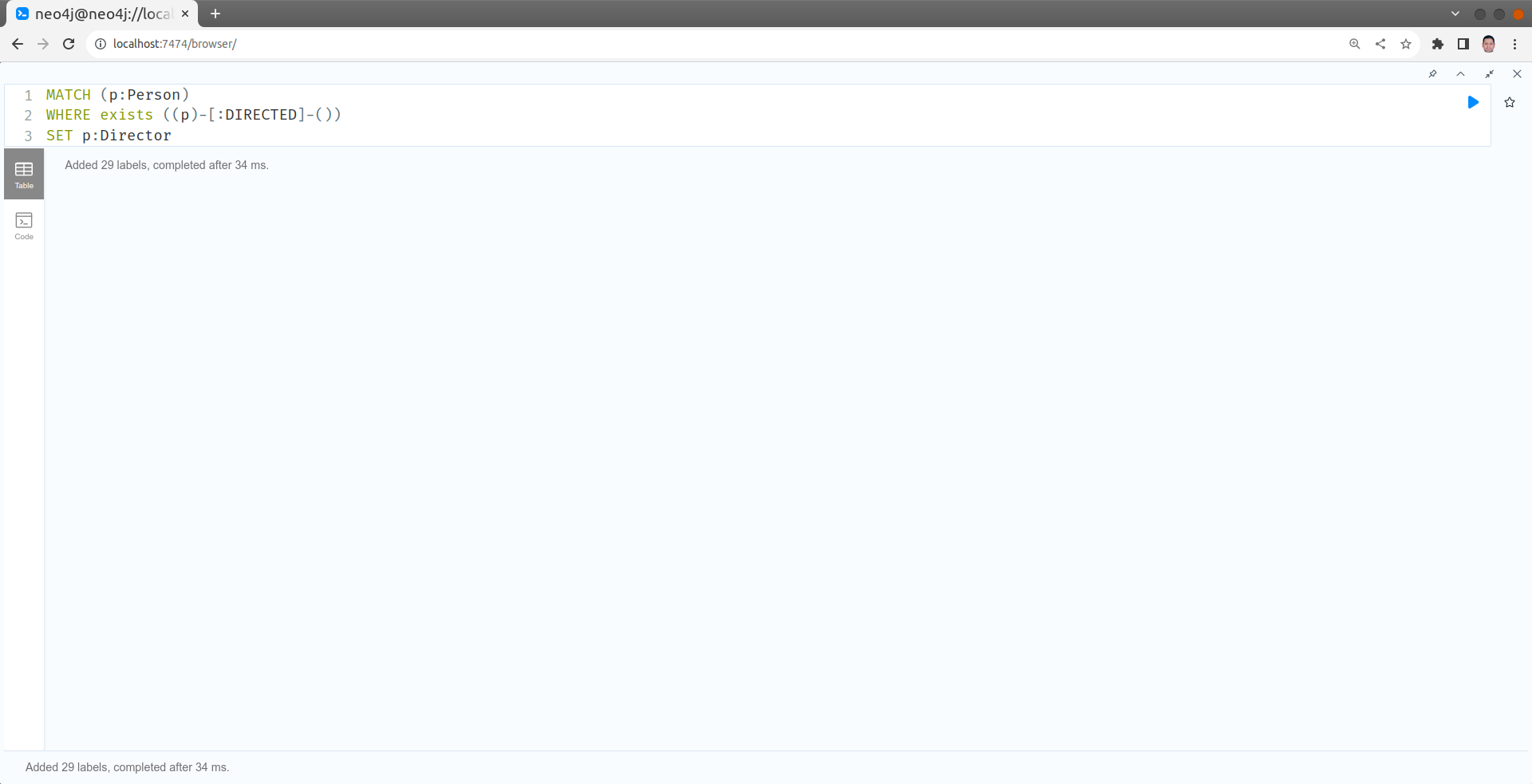
Ajouter un label à noeud : ajouter le label Actor pour tous les Person qui ont au moins joué dans un film.
MATCH (p:Person)
WHERE exists ((p)-[:DIRECTED]-())
SET p:Director
Refactoring
L'ajout de label est une technique utilisée pour optimiser les requêtes par "Refactoring" du graphe. C'est à dire changement du modèle de graphe. Dans l'exemple précédent, nous avons ajouté un label pour toute personne qui a réalisé au moins un film. Nous pouvons donc utiliser ce nouveau label pour interroger directement le graphe avec le pattern (d:Director). Neo4j recommande un nombre maximal de 4 labels par noeuds.
Les figures suivantes permettent de comparer les plans d'exécution des 2 requêtes :
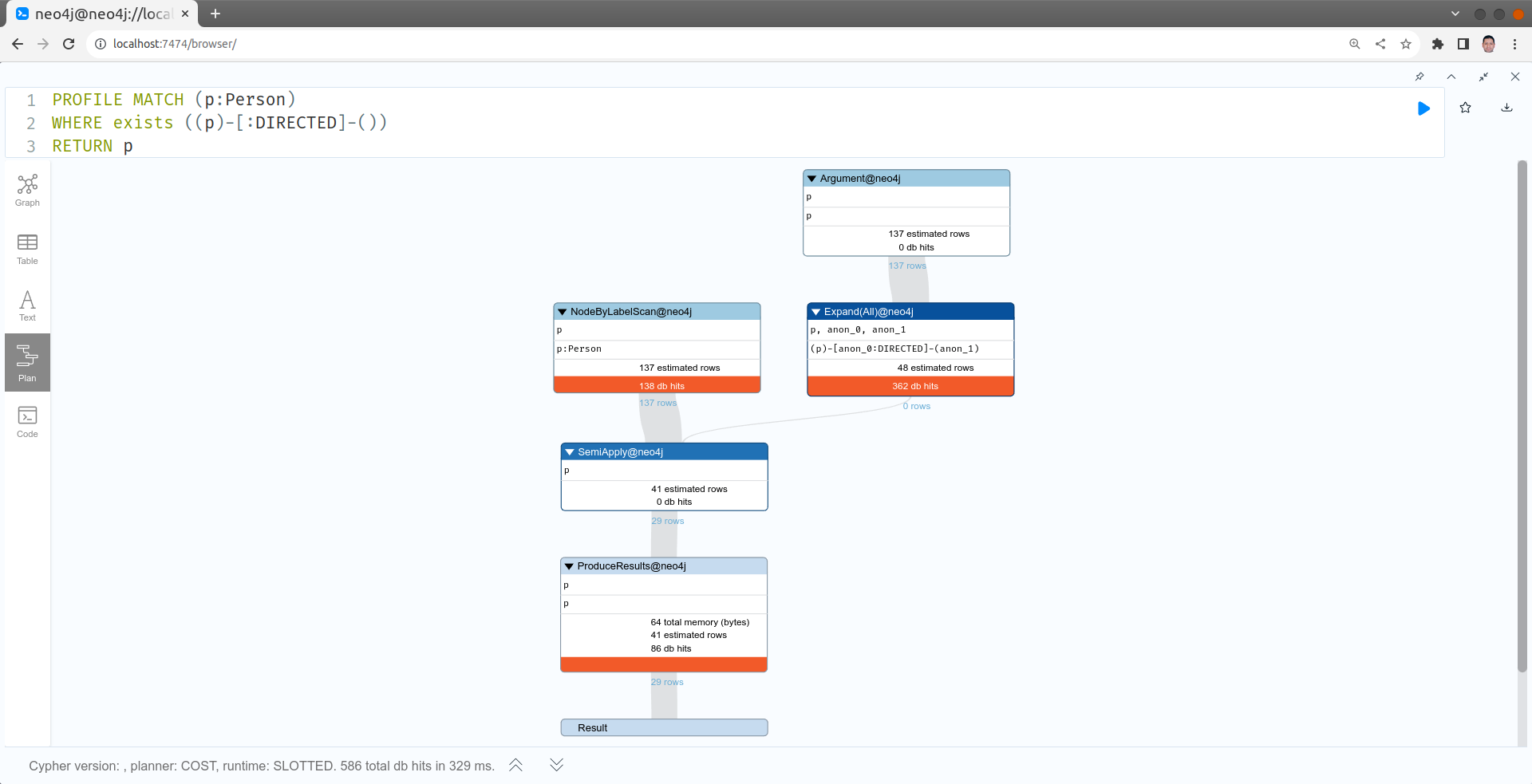
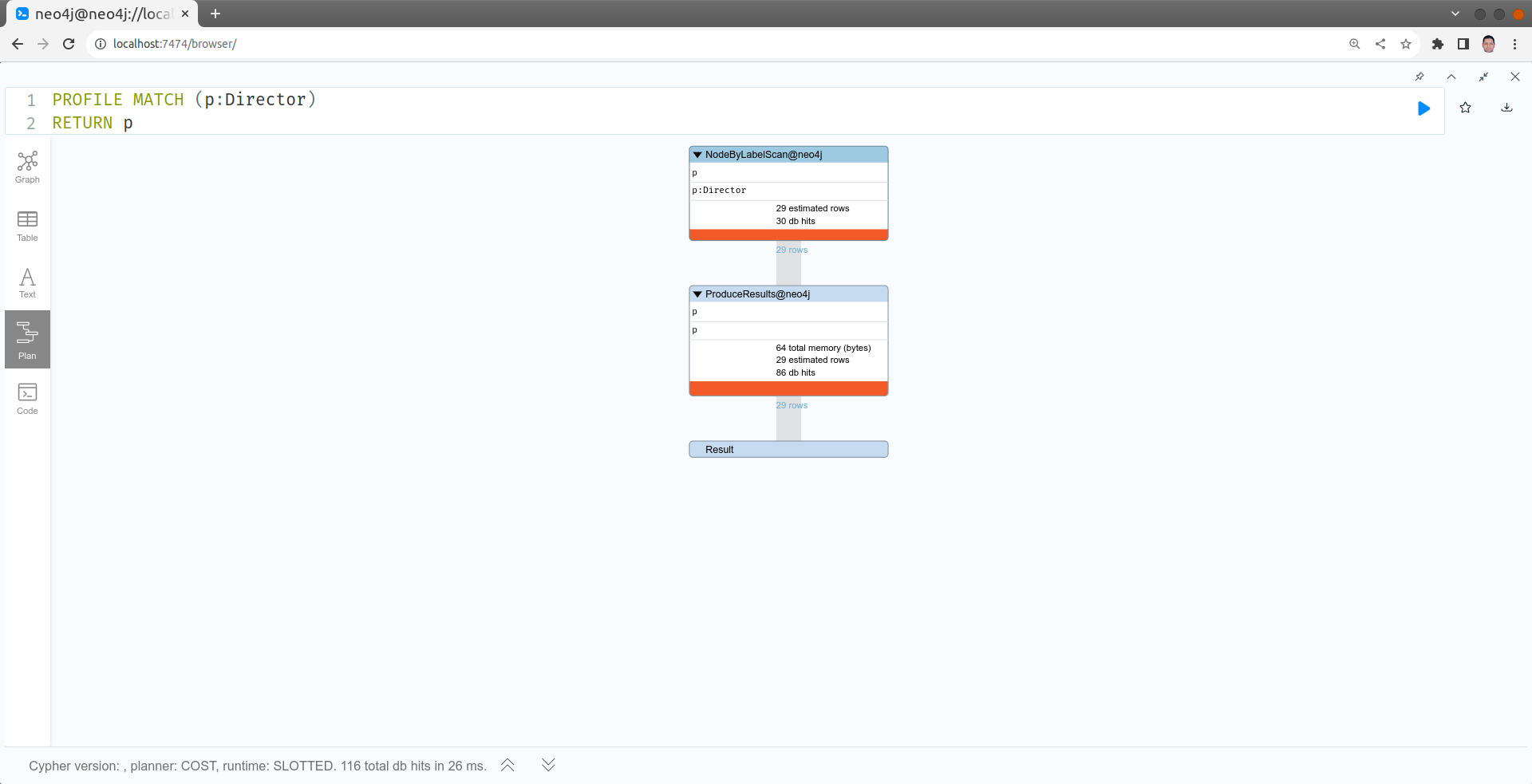
Supprimer tous les labels Director
MATCH (p:Director)
REMOVE p:Director
Suppression¶
C'est DELETE après avoir obtenu une référence vers l'élément à supprimer (avec MATCH par exemple).
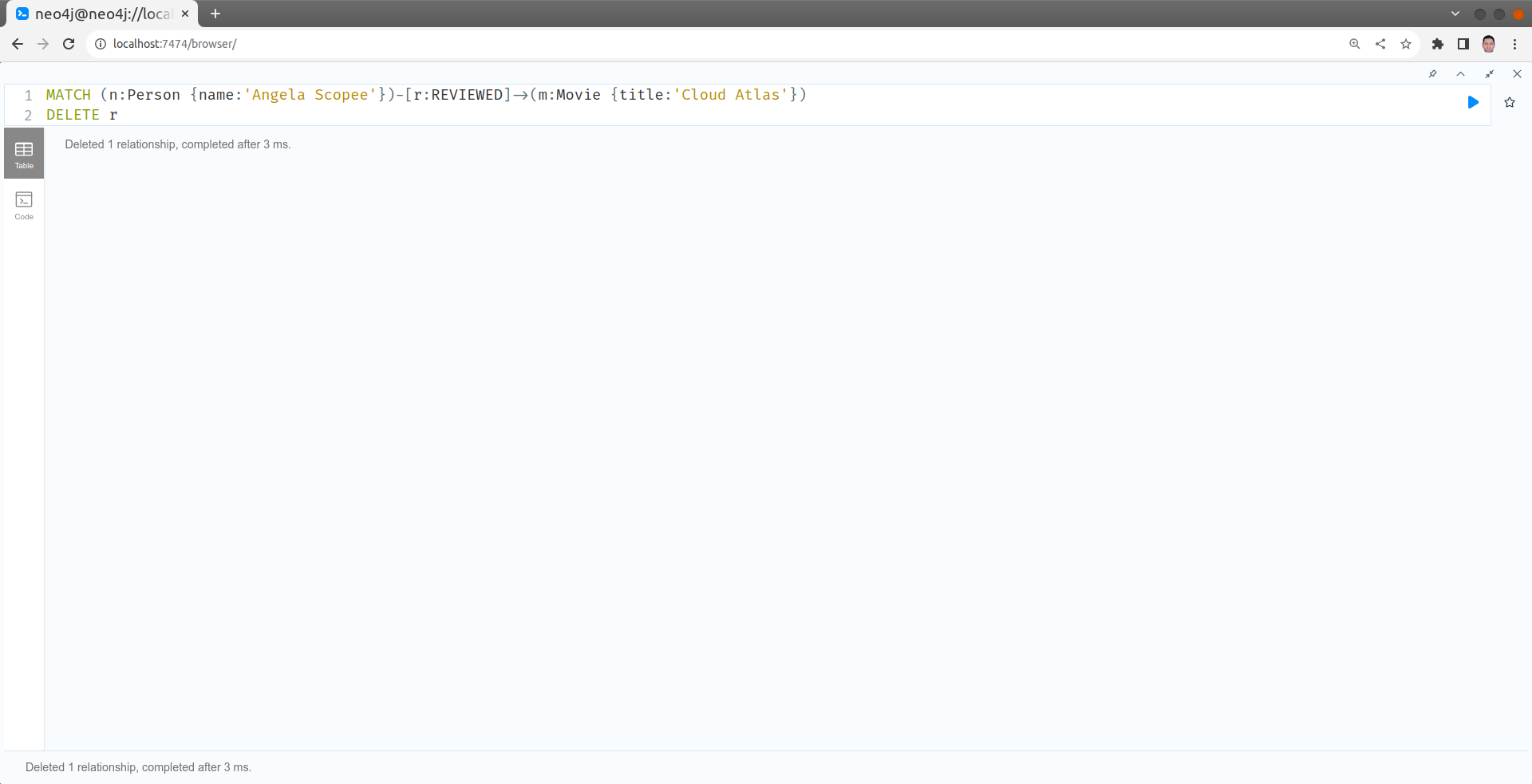
Supprimer le review de "Angela Scope" du film "Cloud Atlas".
MATCH (n:Person {name:'Angela Scopee'})-[r:REVIEWED]->(m:Movie {title:'Cloud Atlas'})
DELETE r
Suppression d'un noeud et ses relations
Quand un noeud possède des relation Neo4j empêche sa suppression. Pour supprimer automatiquement un noeud avec toutes ses relation, il faut utiliser DETACH DELETE
Agrégations¶
Les agrégations sont calculés dans la clause RETURN à travers des fonctions comme : COUNT, SUM, AVG, MIN, MAX, ...
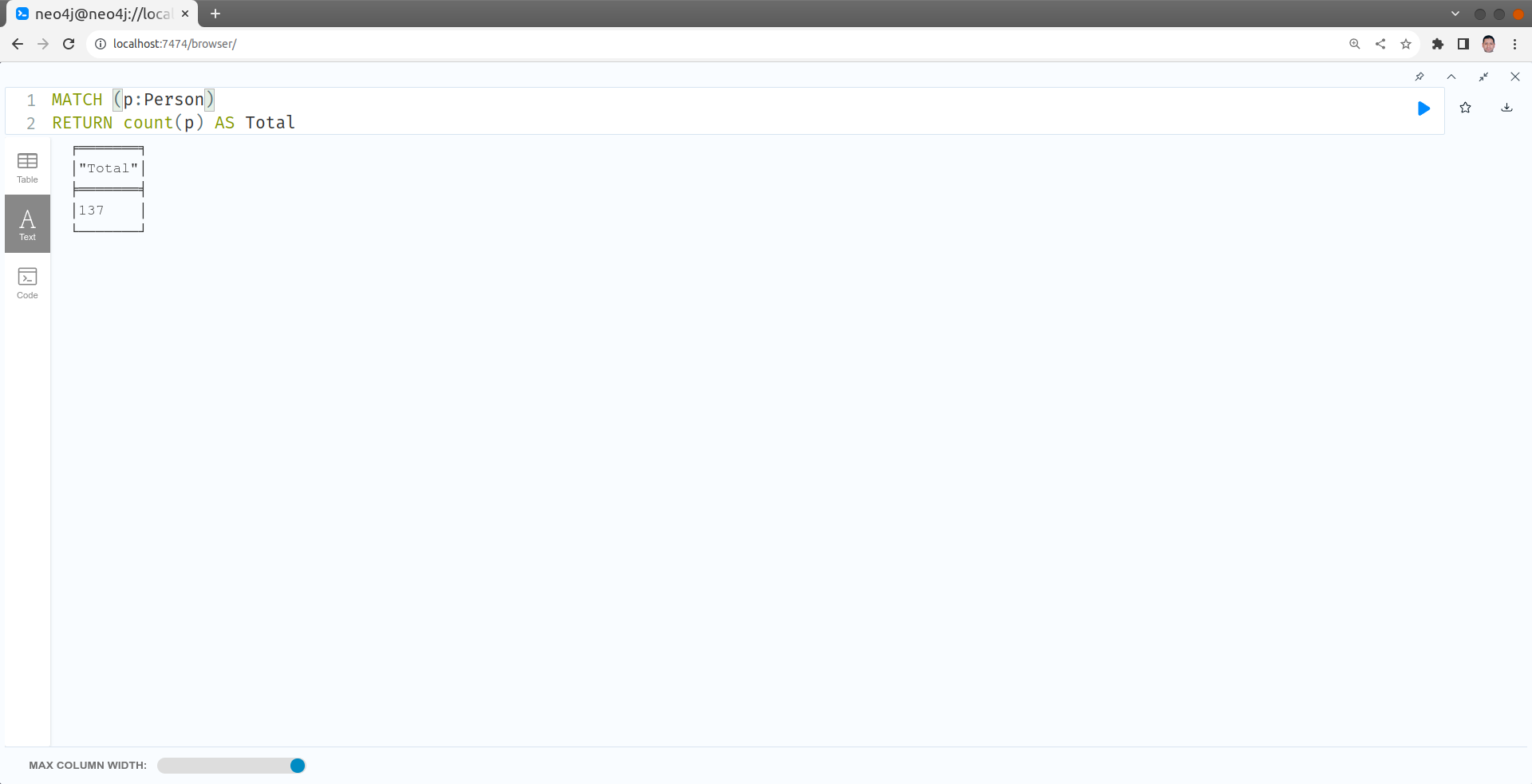
Calculer le nombre de films dans le graphe
MATCH (p:Person)
RETURN count(p) AS Total
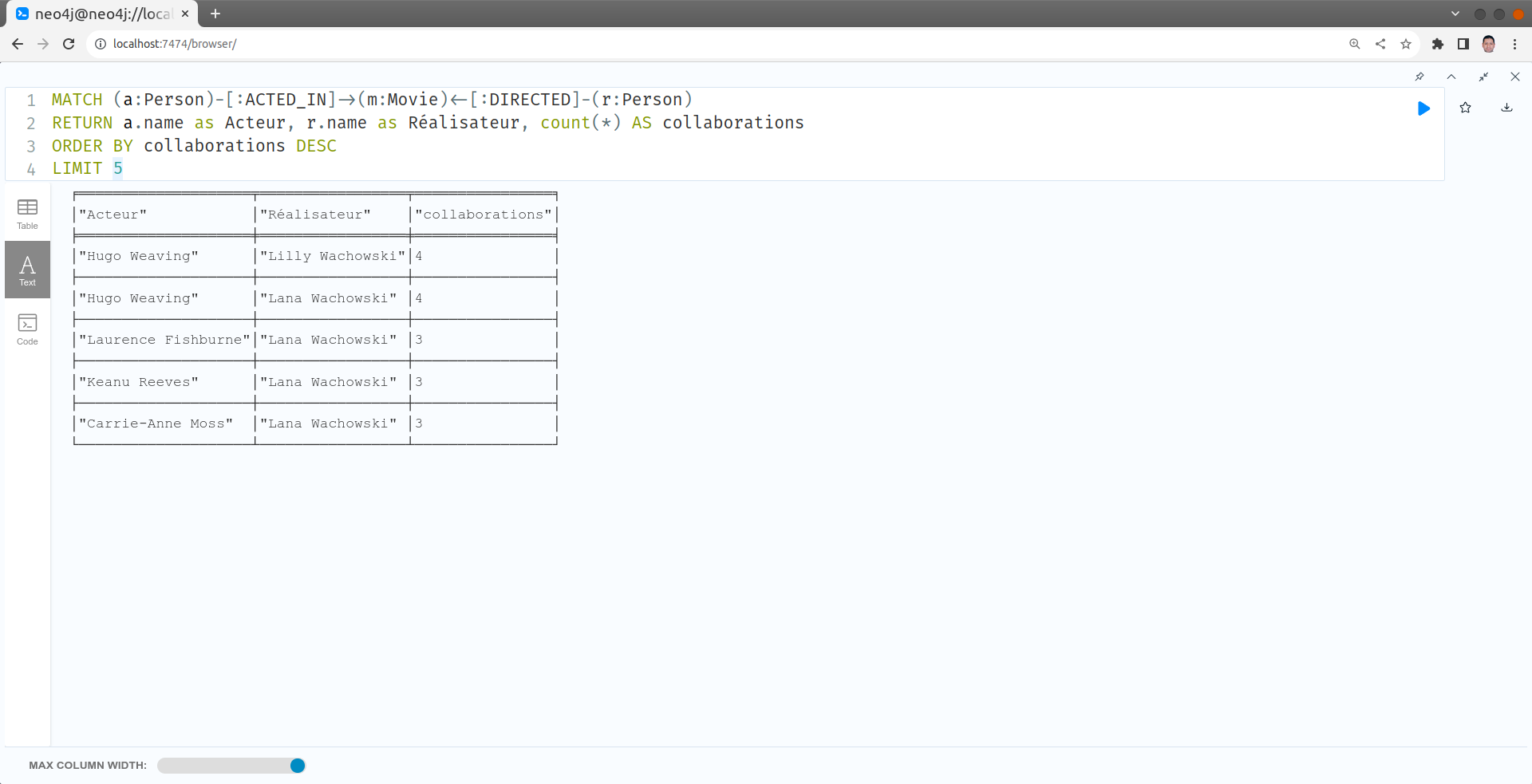
Trouver le top 5 des acteurs et réalisateurs ayant le plus de collaborations
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(r:Person)
RETURN a.name as Acteur, r.name as Réalisateur, count(*) AS collaborations
ORDER BY collaborations DESC
LIMIT 5
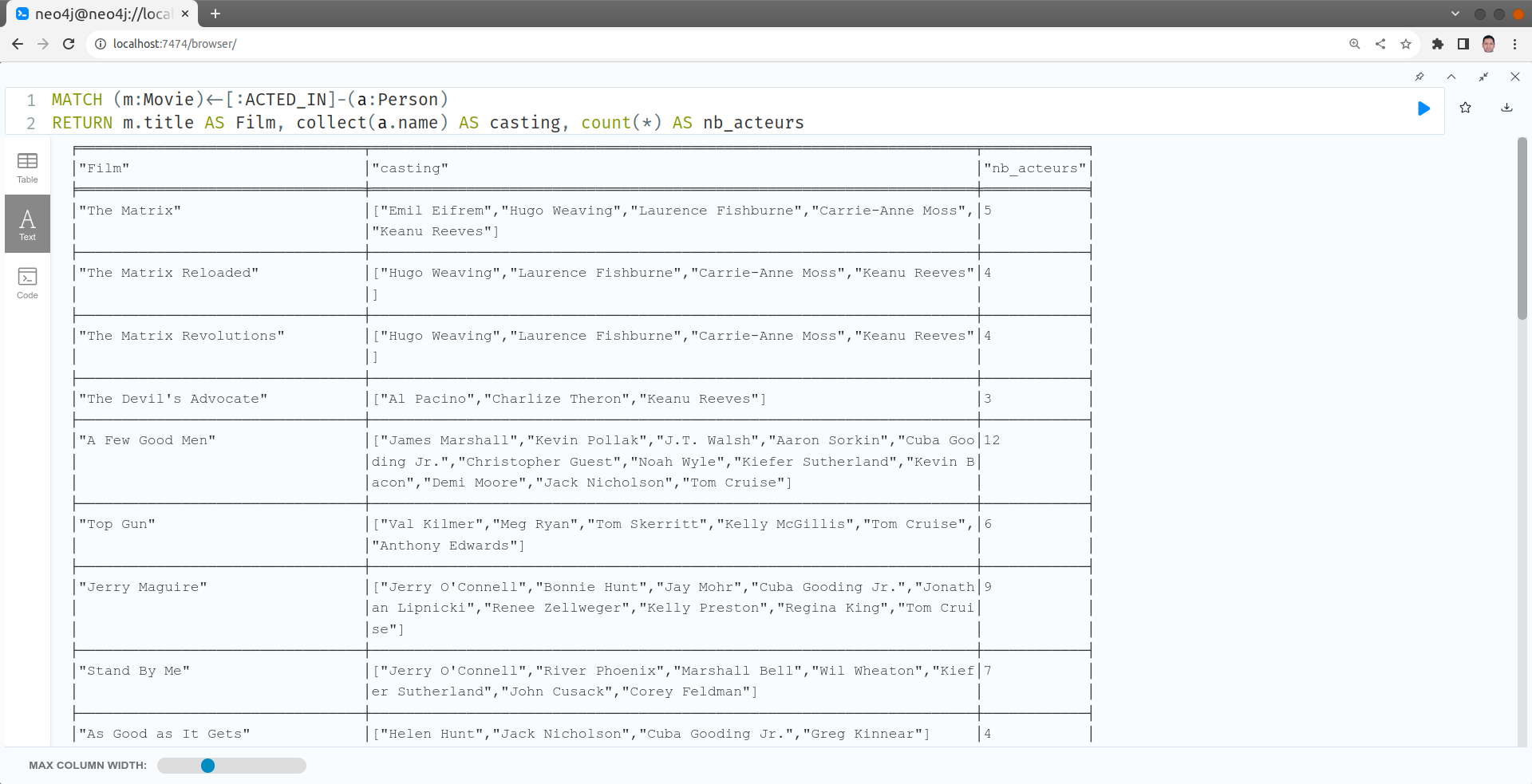
Pour chaque film afficher les acteurs et leur nombre
MATCH (m:Movie)<-[:ACTED_IN]-(a:Person)
RETURN m.title AS Film, collect(a.name) AS casting, count(*) AS nb_acteurs
collect
La fonction collect permet de créer une liste des valeurs pour des structures de type parent-enfants ou 1-n. Dans cet exemple, un film (titre) a plusieurs acteurs. Collect permet de grouper les acteurs dans une liste pour ne pas répéter le film avec chaque acteur. C'est comme effectuer un GROUP BY sur le titre du film mais sans perdre le détail des enfants (acteurs).
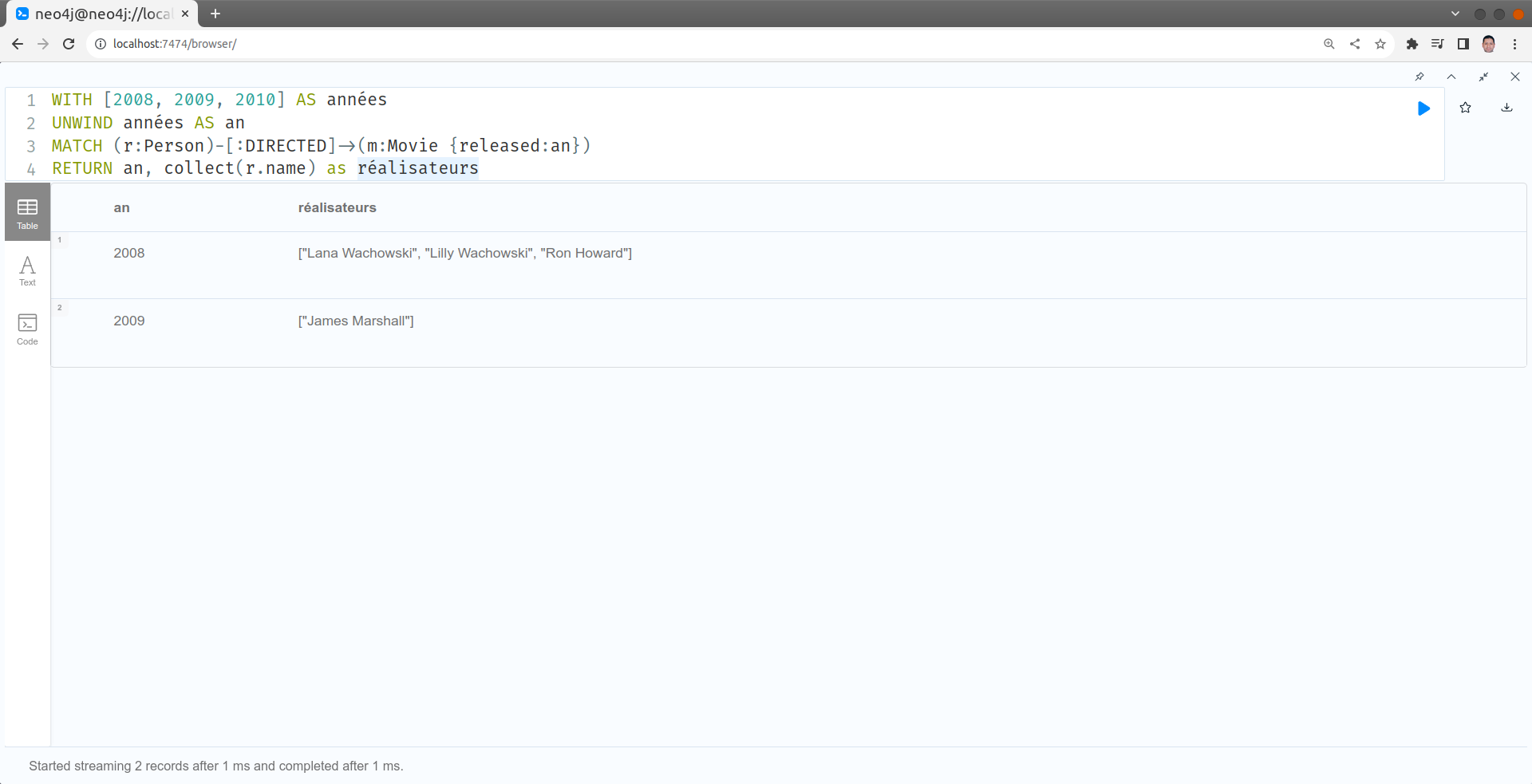
Quels sont les réalisateurs de films sortis en 2008, 2009 et 2010
WITH [2008, 2009, 2010] AS années
UNWIND années AS an
MATCH (r:Person)-[:DIRECTED]->(m:Movie {released:an})
RETURN an, collect(r.name) as réalisateurs
Index et contraintes¶
Les index permettent d'accélérer les requêtes et sont un outil indispensabe pour l'optimisation des requêtes.
Neo4j utilise 5 types d'index :
- RANGE
- LOOKUP
- TEXT
- FULLTEXT
- POINT
CREATE [RANGE|LOOKUP|TEXT|FULLTEXT|POINT] INDEX <nom_index> FOR (n:label) ON (l.prop1, ...)
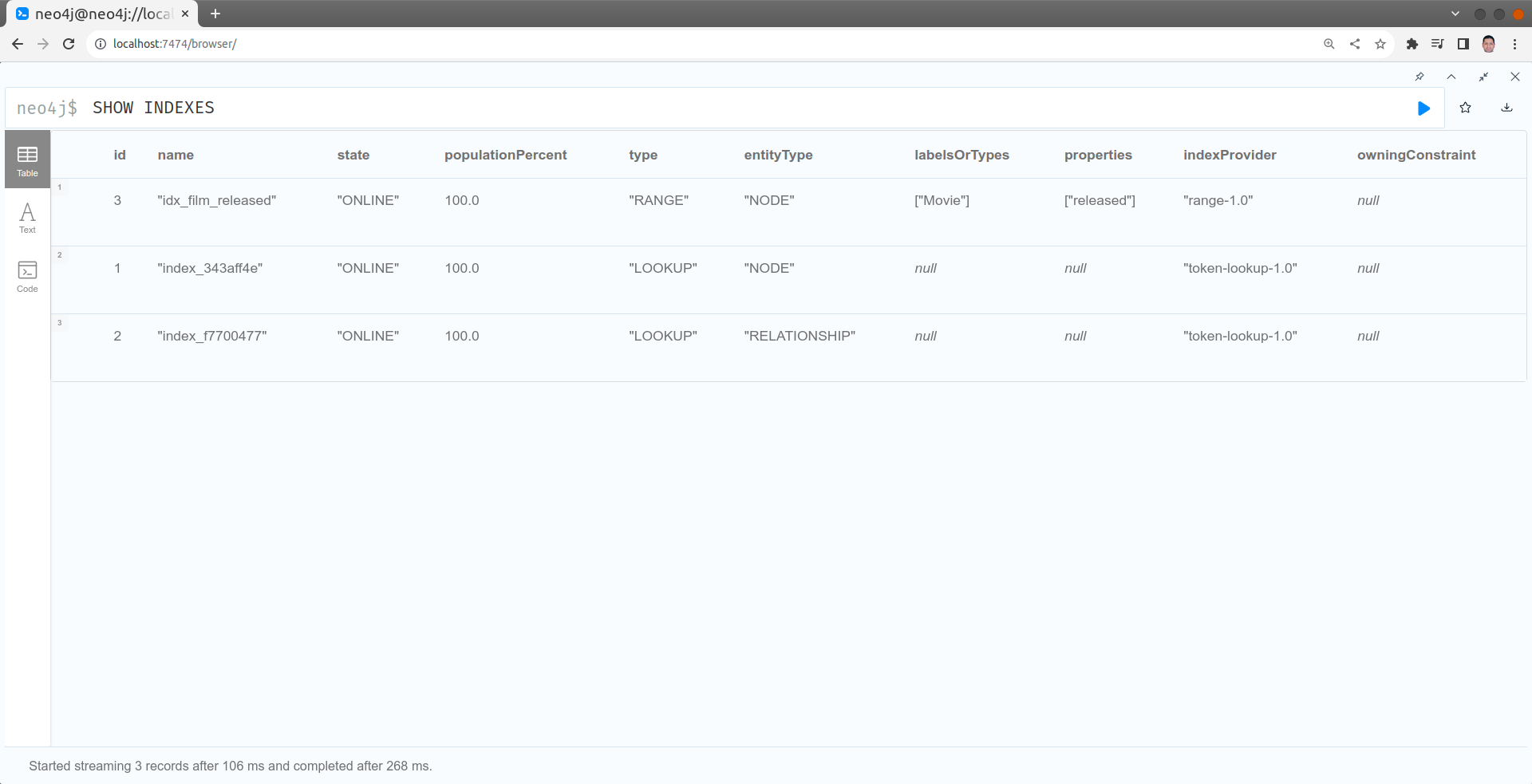
Créer un index sur la date de sortie d'un film
CREATE INDEX idx_film_released FOR (m:Movie) ON (m.released)
SHOW INDEXES
Ajouter une contrainte d'unicité d'une propriété
CREATE CONSTRAINT [constraint_name] [IF NOT EXISTS]
FOR (n:LabelName)
REQUIRE (n.propertyName_1, …, n.propertyName_n) IS UNIQUE
[OPTIONS "{" option: value[, ...] "}"]
Autres types de contraintes
D'autres contraintes sont disponibles mais uniquement dans la version Enterprise comme :
- Existence de propriété de noeud
- Existence de propriété de relation
- Contrainte Node Key
Références du lanagage Cypher¶
Types¶
Dans Neo4j, les types suivants sont supportés :
- Number
- String
- Boolean
- The spatial type Point
- Date, Time, LocalTime, DateTime, LocalDateTime et Duration
- Lsit et Map
Opérateurs¶
| Catégorie | Opérateurs |
|---|---|
| Agrégation | DISTINCT |
| Propriétés | . accès, []: accès dynamique, =: affectation, +=: affectation de certains types de propriétés |
| Mathématiques | +, -, *, /, %, ^ |
| Comparaison | <>, <, >, <=, >=, IS NULL, IS NOT NULL |
| Chaînes de caractères | STARTS WITH, ENDS WITH, CONTAINS, =~ pour les expressions régulières, + concaténation |
| Booléens | AND, OR, XOR, NOT |
| Dates et durées | + et - entre dates et durées, * et / entre durées et nombres |
| Dictionnaires (Map) | . accès statique par clé, [] accès dynamique par clé |
| Tableaux (List) | + concaténation, IN test d'appartenance, [] accès à un élément |
Fonctions¶
| Famille | Exemples |
|---|---|
| Prédicats | all(), any(), exists(), isEmpty(), single() |
| String | left(), right(), substring(), trim(), toUpper(), toLower(), split(), replace(), ... |
| List/Map | keys(), labels(), nodes(), range(), relationships(), reverse(), size(), head(), last(), ... |
| Maths | abs(), ceil(), floor(), round(), rand(), isNaN(), ... |
| Agrégats | min(), max(), sum(), count(), avg(), stdev(), ... |
| Date/Time | date(), datetime(), time(), datetime.fromepochmillis(), duration(), duration.between(), .... |
Manipulation de bases de données¶
- Lister les BD
SHOW { DATABASE name | DATABASES | DEFAULT DATABASE | HOME DATABASE } [WHERE expression]SHOW { DATABASE name | DATABASES | DEFAULT DATABASE | HOME DATABASE } YIELD { * | field[, ...] } [ORDER BY field[, ...]] [SKIP n] [LIMIT n] [WHERE expression] [RETURN field[, ...] [ORDER BY field[, ...]] [SKIP n] [LIMIT n]] - Créer une BD
CREATE DATABASE name [IF NOT EXISTS] [TOPOLOGY n PRIMAR{Y|IES} [m SECONDAR{Y|IES}]] [OPTIONS "{" option: value[, ...] "}"] [WAIT [n [SEC[OND[S]]]]|NOWAIT]CREATE OR REPLACE DATABASE name [TOPOLOGY n PRIMAR{Y|IES} [m SECONDAR{Y|IES}]] [OPTIONS "{" option: value[, ...] "}"] [WAIT [n [SEC[OND[S]]]]|NOWAIT]CREATE COMPOSITE DATABASE name [IF NOT EXISTS] [WAIT [n [SEC[OND[S]]]]|NOWAIT]CREATE OR REPLACE COMPOSITE DATABASE name [WAIT [n [SEC[OND[S]]]]|NOWAIT] - Modifier une BD
ALTER DATABASE name [IF EXISTS] { SET ACCESS {READ ONLY | READ WRITE} | SET TOPOLOGY n PRIMAR{Y|IES} [m SECONDAR{Y|IES}] } - Démarrer une BD
START DATABASE name [WAIT [n [SEC[OND[S]]]]|NOWAIT] - Arrêter une BD
STOP DATABASE name [WAIT [n [SEC[OND[S]]]]|NOWAIT] - Supprimer une BD
DROP [COMPOSITE] DATABASE name [IF EXISTS] [{DUMP|DESTROY} [DATA]] [WAIT [n [SEC[OND[S]]]]|NOWAIT]
Exercice  ¶
¶
Soit la base de données Northwind dont le schéma est le suivant :
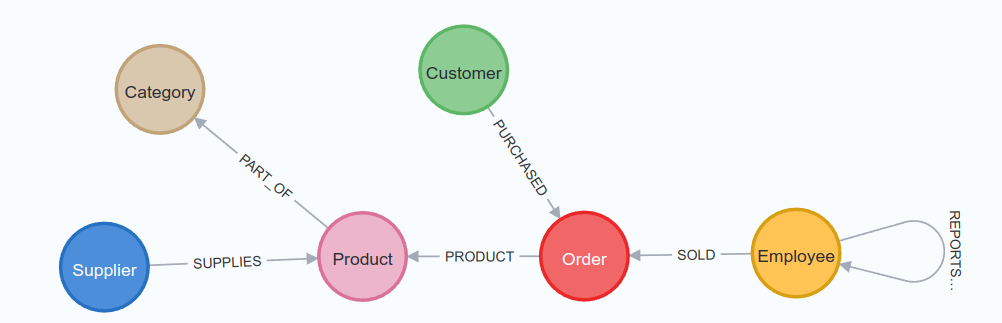
- Créer un nouveau container Neo4j pour l'exercice
- Imorter les données en exécutant le code suivant :
// tag::constraints[] CREATE CONSTRAINT FOR (o:Order) REQUIRE o.orderID IS UNIQUE; // end::constraints[] // tag::indexes[] CREATE INDEX FOR (m:Product) ON (m.productID); CREATE INDEX FOR (m:Product) ON (m.productName); CREATE INDEX FOR (m:Category) ON (m.categoryID); CREATE INDEX FOR (m:Employee) ON (m.employeeID); CREATE INDEX FOR (m:Supplier) ON (m.supplierID); CREATE INDEX FOR (m:Customer) ON (m.customerID); CREATE INDEX FOR (m:Customer) ON (m.customerName); // end::indexes[] // tag::nodes[] // Create customers LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-documentation/developer-resources/raw/gh-pages/data/northwind/customers.csv" AS row CREATE (:Customer {companyName: row.CompanyName, customerID: row.CustomerID, fax: row.Fax, phone: row.Phone}); // Create products LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-documentation/developer-resources/raw/gh-pages/data/northwind/products.csv" AS row CREATE (:Product {productName: row.ProductName, productID: row.ProductID, unitPrice: toFloat(row.UnitPrice)}); // Create suppliers LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-documentation/developer-resources/raw/gh-pages/data/northwind/suppliers.csv" AS row CREATE (:Supplier {companyName: row.CompanyName, supplierID: row.SupplierID}); // Create employees LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-documentation/developer-resources/raw/gh-pages/data/northwind/employees.csv" AS row CREATE (:Employee {employeeID:row.EmployeeID, firstName: row.FirstName, lastName: row.LastName, title: row.Title}); // Create categories LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-documentation/developer-resources/raw/gh-pages/data/northwind/categories.csv" AS row CREATE (:Category {categoryID: row.CategoryID, categoryName: row.CategoryName, description: row.Description}); LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-documentation/developer-resources/raw/gh-pages/data/northwind/orders.csv" AS row MERGE (order:Order {orderID: row.OrderID}) ON CREATE SET order.shipName = row.ShipName; // end::nodes[] // tag::rels_orders[] LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-documentation/developer-resources/raw/gh-pages/data/northwind/orders.csv" AS row MATCH (order:Order {orderID: row.OrderID}) MATCH (product:Product {productID: row.ProductID}) MERGE (order)-[pu:PRODUCT]->(product) ON CREATE SET pu.unitPrice = toFloat(row.UnitPrice), pu.quantity = toFloat(row.Quantity); LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-documentation/developer-resources/raw/gh-pages/data/northwind/orders.csv" AS row MATCH (order:Order {orderID: row.OrderID}) MATCH (employee:Employee {employeeID: row.EmployeeID}) MERGE (employee)-[:SOLD]->(order); LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-documentation/developer-resources/raw/gh-pages/data/northwind/orders.csv" AS row MATCH (order:Order {orderID: row.OrderID}) MATCH (customer:Customer {customerID: row.CustomerID}) MERGE (customer)-[:PURCHASED]->(order); // end::rels_orders[] // tag::rels_products[] LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-documentation/developer-resources/raw/gh-pages/data/northwind/products.csv" AS row MATCH (product:Product {productID: row.ProductID}) MATCH (supplier:Supplier {supplierID: row.SupplierID}) MERGE (supplier)-[:SUPPLIES]->(product); LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-documentation/developer-resources/raw/gh-pages/data/northwind/products.csv" AS row MATCH (product:Product {productID: row.ProductID}) MATCH (category:Category {categoryID: row.CategoryID}) MERGE (product)-[:PART_OF]->(category); // end::rels_products[] // tag::rels_employees[] LOAD CSV WITH HEADERS FROM "https://github.com/neo4j-documentation/developer-resources/raw/gh-pages/data/northwind/employees.csv" AS row MATCH (employee:Employee {employeeID: row.EmployeeID}) MATCH (manager:Employee {employeeID: row.ReportsTo}) MERGE (employee)-[:REPORTS_TO]->(manager); // end::rels_employees[] - Répondre aux requêtes suivantes :
- Trouver les produits et leurs prix.
- Trouver les informations sur les produits 'Chocolade' & 'Pavlova'.
- Trouver les informations sur les produits dont le nom commence par "C” et le prix >50.
- Requête précédente en considérant "sales price" au lieu du prix du produit.
- Montant Total des achats par client et produit.
- Top 10 des employés selon les commandes vendues.
- Un employé est rattaché à combien de personnes de façon directe ou indirecte.
- À qui les personnes nommées “Robert” sont-ils rattachées.
- Qui n'a pas de personne à qui il est rattachée ?
- Trouver les fournisseurs (Suppliers), le nombre de catégories qu'ils fournissent et la liste de ces catégories.
- Le client qui a acheté le plus grand montant de la catégorie "beverages".
- Les 5 produits les plus populaires selon le nombre de commandes.