
Importation de données vers Neo4j¶
L'importation de donnnées dans Neo4j¶
Lorsque vous importer des données dans Neo4j, vous avez typiquement un ensemble de fichiers sources qui ont été obtenus à partir de :
- SGBDR
- APIs Web
- Répertoires de données publics
- Outils de BI
- Excel
Les types de fichiers sont typiquement CSV, JSON, XML, etc. Dans ce cours, vous apprendrer à importer des données CSV dans Neo4j en tant que noeuds, relations et leurs propriétés. Cypher possède une clause intégrée, LOAD CSV pour importer des fichiers CSV. Si vous avez un fichier JSON ou XML, vous dever utiliser la bibliothèque APOC pour importer les données, mais vous pouver aussi importer des CSV avec APOC. Et Neo4j Data Importer vous permet d'importer des données CSV sans écrire aucun code Cypher.
Les données dans les fichiers sources peuvent contenir plus de données que ce dont vous avez besoin dans votre graphique. Il peut ne pas y avoir de correspondance 1-1 entre les données d'un fichier CSV et ce que vous utiliserier comme nœud dans un modèle de données de graphe. De plus, les données dans les fichiers sources peuvent représenter des types de données qui ne sont pas supportés par Neo4j ou spécifiés dans le modèle de données que vous implémenter. Certaines données dans les fichiers sources peuvent avoir besoin d'être transformées dans les types appropriés.
Les types de données que vous pouver stocker comme propriétés dans Neo4j incluent :
- String
- Long
- Double
- Boolean
- Date/Datetime
- Point (Geospatial)
- StringArray
- LongArray
- DoubleArray
Après avoir compris les données sources sur lesquelles vous dever travailler ainsi que le modèle de données graphique que vous aller implémenter, vous pouver importer les données dans Neo4j. Il y a deux façons d'importer des données CSV dans Neo4j que vous aller apprendre dans ce cours :
- Utiliser Neo4j Data Importer soit :
- En ligne : https://data-importer.graphapp.io/
- Application Neo4j ETL Tool à installer sur Neo4j Desktop et disponible sur : https://install.graphapp.io/
- En écrivant du code Cypher pour effectuer l'importation.
Dans les deux cas, l'importation implique la lecture des données sources et leur utilisation pour créer des noeuds, des relations et des propriétés dans le graphe.
Importation avec Neo4j Data Importer¶
Le modèle de données graphique que vous aller mettre en œuvre est le suivant :
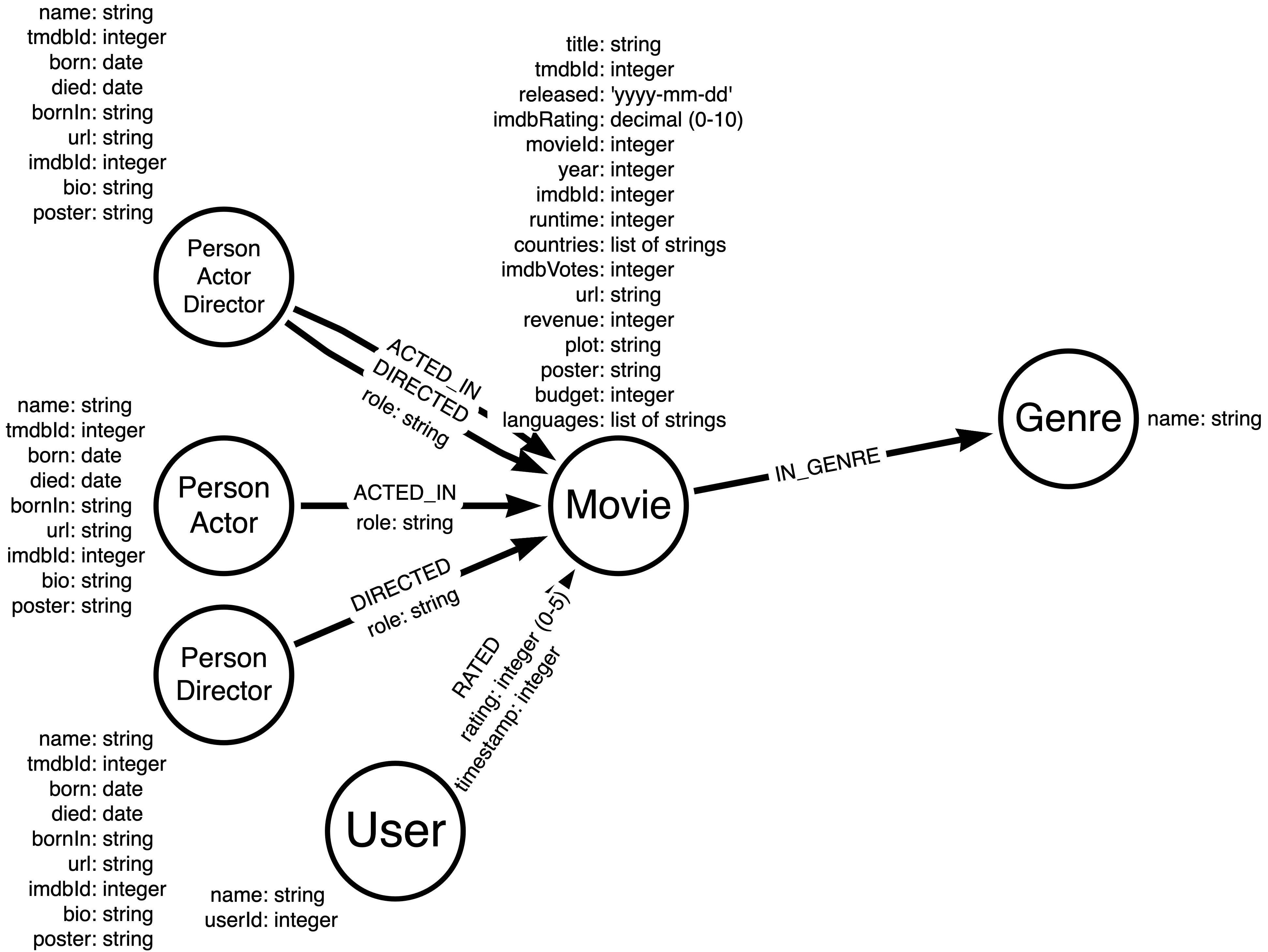
Remarquer les types des propriétés. Lorsque vous définisser le mapping pour l'importation, vous dever tenir compte des types qui peuvent être automatiquement mappés (chaîne, entier, décimal, date) et du fait que les valeurs clés de vos propriétés peuvent être différentes de celles des fichiers CSV.
 Télécharger les fichiers CSV
Télécharger les fichiers CSV
- Télécharger le fichier suivant movieData.zip sur votre système :
- Décompresser ce fichier pour obtenir les fichiers :
- persons.csv
- movies.csv
- ratings.csv
- directed.csv
- acted_in.csv
 Accéder à Neo4j Data Importer : http://data-importer.graphapp.io/
Accéder à Neo4j Data Importer : http://data-importer.graphapp.io/
Connexion
Pour une connexion locale non sécurisée, utiliser le protocole http et non https.
Dans une fenêtre de navigateur Web, ouvrer le Data Importer de Neo4j. Puis entrer les information de connexion à votre instance locale :
Ensuite, vous devrier voir ceci :
 Charger les fichiers CSV dans l'importateur de données
Charger les fichiers CSV dans l'importateur de données
Dans l'onglet gauche Files, ajouter les cinq fichiers CSV que vous avez décompressés à l'étape 1.
Après les avoir ajoutés, vous devrier voir ceci :
 Définir le mapping des nœuds Person
Définir le mapping des nœuds Person
- Cliquer sur l'icône
Add nodedans le volet Modèle de graphique. - Dans le volet Détails du mapping, à droite :
- Saisisser Person pour Label.
- Sélectionner le fichier persons.csv.
- Sous Properties, cliquer sur
Select from file.- Sélectionner Tout.
- Cliquer sur Confirmer.
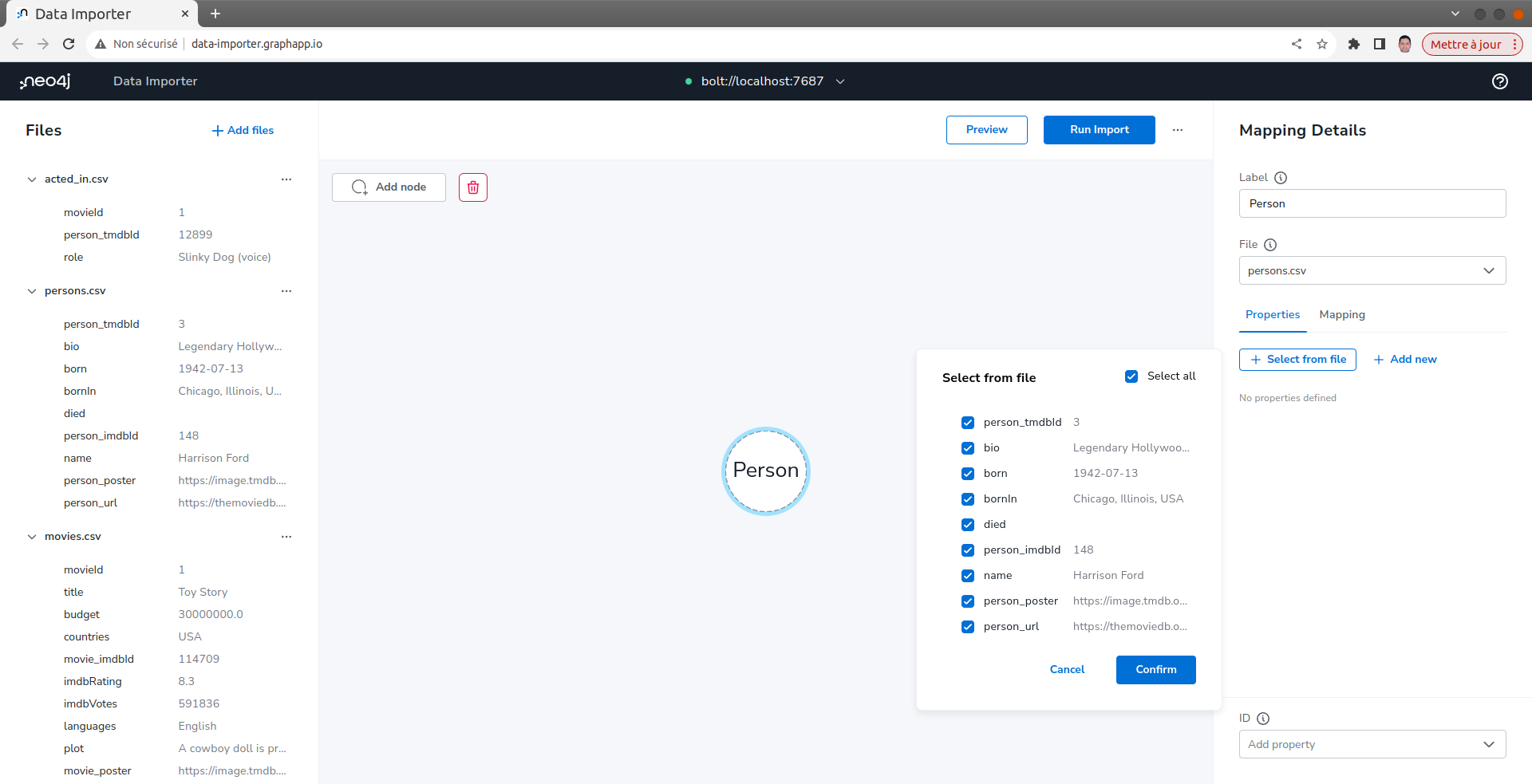
Remarquer que certains noms de propriétés ne correspondent pas au modèle de données du graphique. Modifier-les comme suit :
- person_tmdbId tmdbId
- person_imdbId imdbId
- person_poster poster
- person_url url
Sélectionner tmdbId comme l'identifiant unique qui sera utilisé pour ces nœuds Person.
Vous devrier voir un indicateur vert dans le panneau de gauche indiquant que toutes les propriétés ont été mappées : 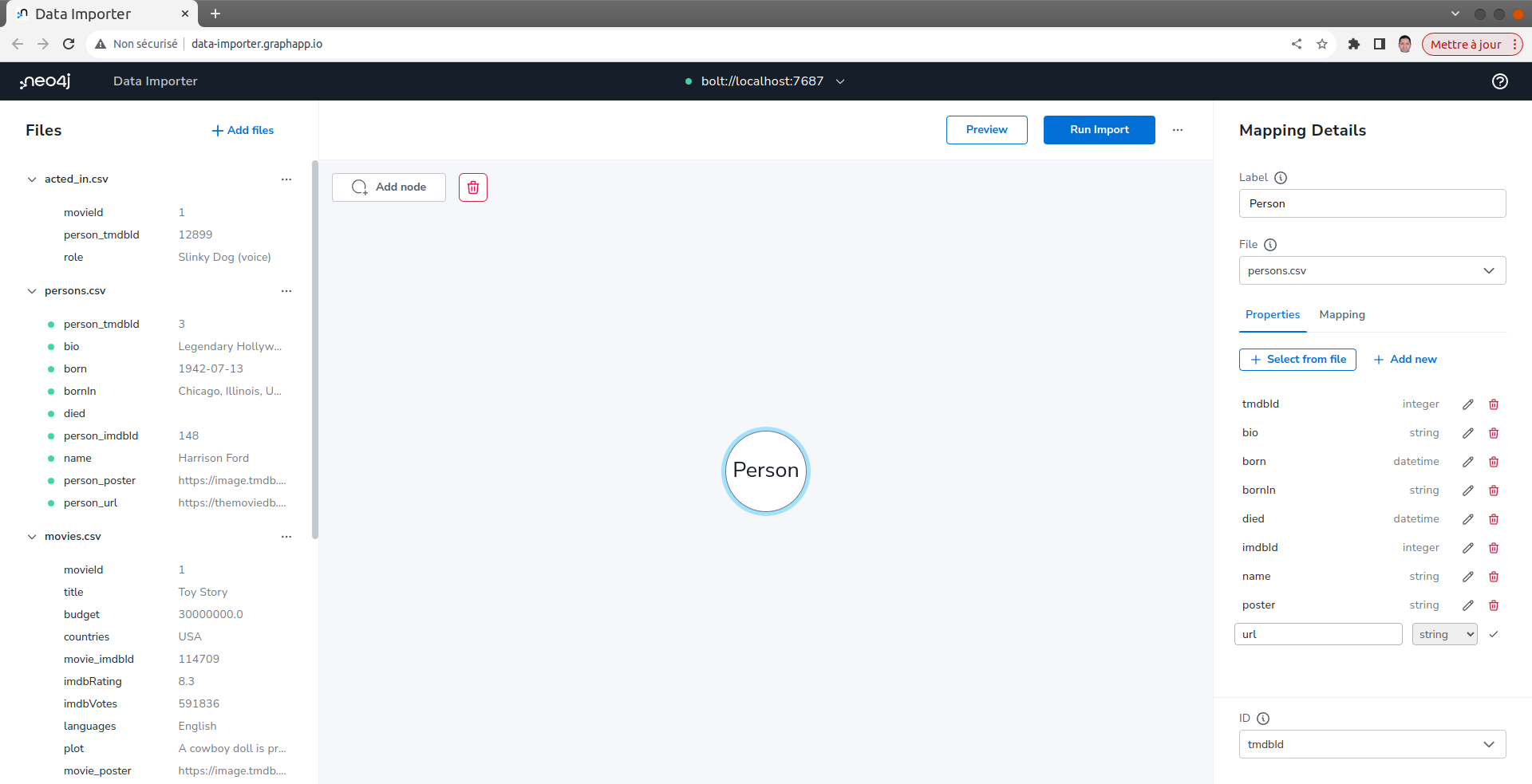
 Définir le mapping des nœuds Movie
Définir le mapping des nœuds Movie
- Répéter les étapes précédentes du nœud Person en utilisant le fichier movies.csv.
- Modifier les propriétés comme suit :
- movie_tmdbId :right-arrow: tmdbId
- movie_imdbId imdbId
- movie_poster poster
- movie_url url
- Remarquer également que certains types de propriétés ne correspondent pas à ce que notre modèle de données défini. Modifier les types de propriétés comme suit :
- budget integer
- revenue integer
- Sélectionner movieId comme l'identifiant unique qui sera utilisé pour ces nœuds Movie. Noter que nous avons sélectionné movieID comme ID unique car il est utilisé dans les autres fichiers lorsque nous définissons les relations avec les films.
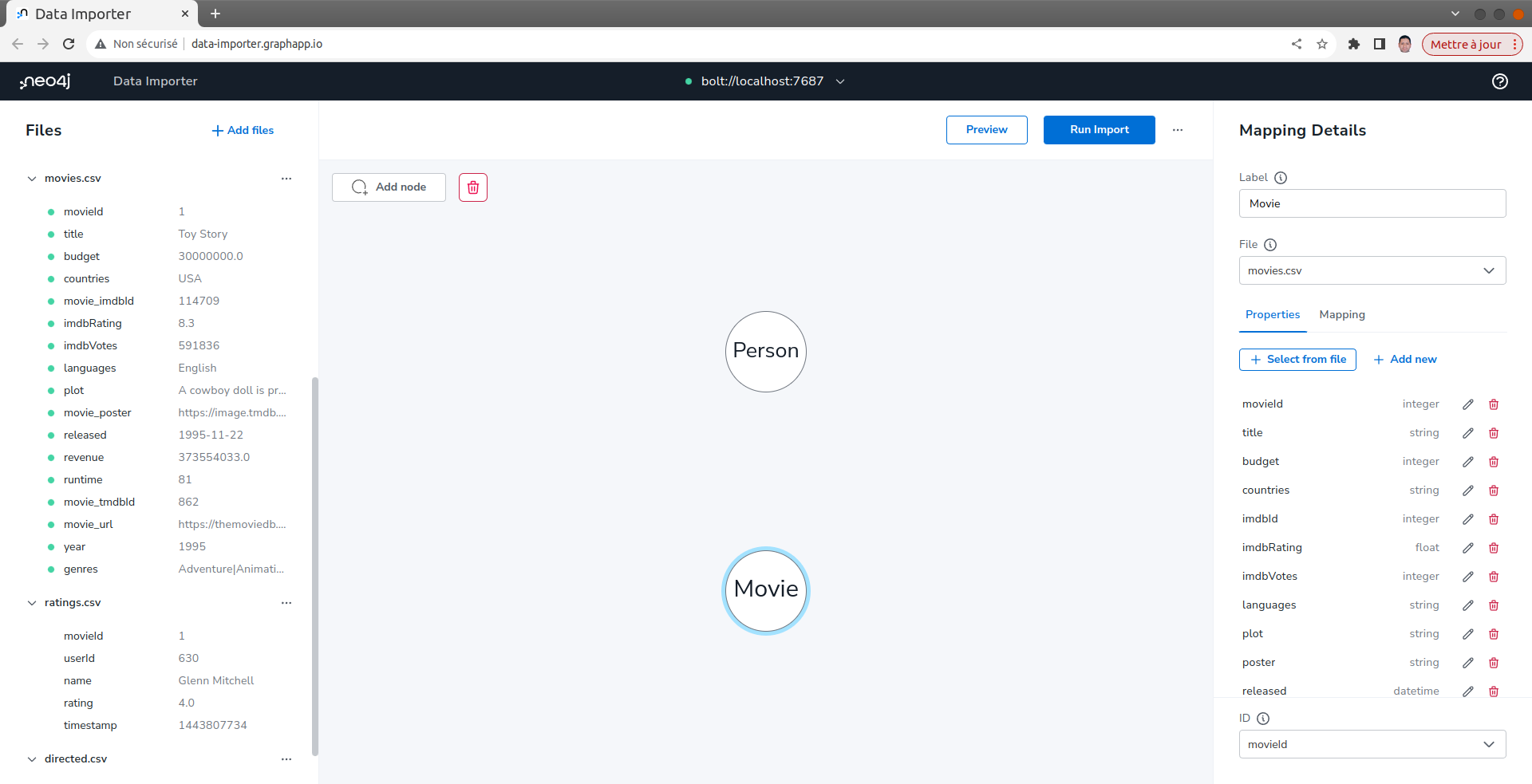
 Définir le mapping des nœuds User
Définir le mapping des nœuds User
Dans le volet Détails du mapping, à droite :
- Entrer User pour l'étiquette.
- Sélectionner le fichier ratings.csv.
- Sous Propriétés, cliquer sur Ajouter à partir du fichier.
- Sélectionner uniquement les propriétés userId et name. Les autres valeurs seront utilisées ultérieurement pour définir les relations.
- Cliquer sur Confirmer.
- Confirmer que userId a été sélectionné comme ID ; il s'agit de l'ID unique qui sera utilisé pour ces nœuds User.
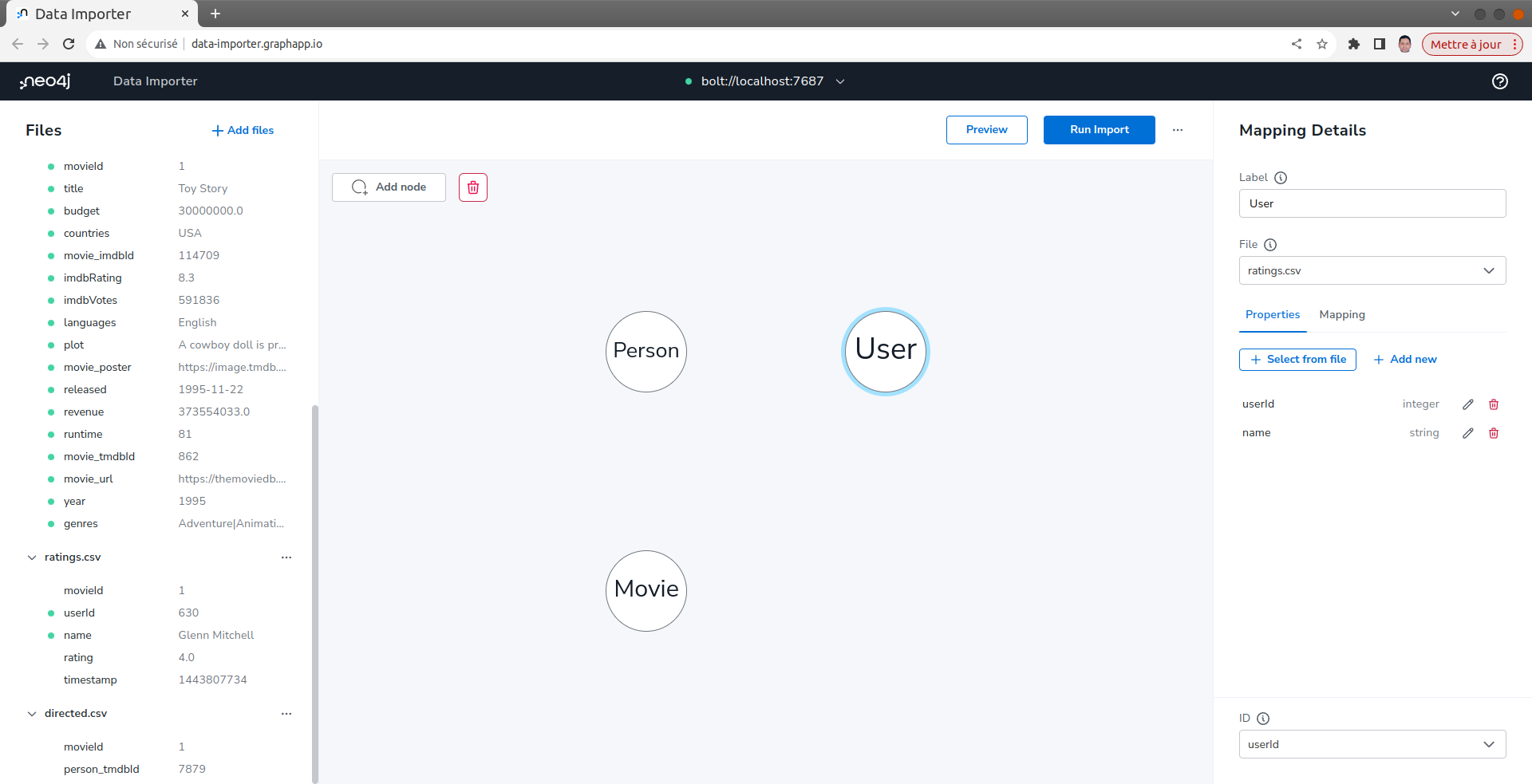
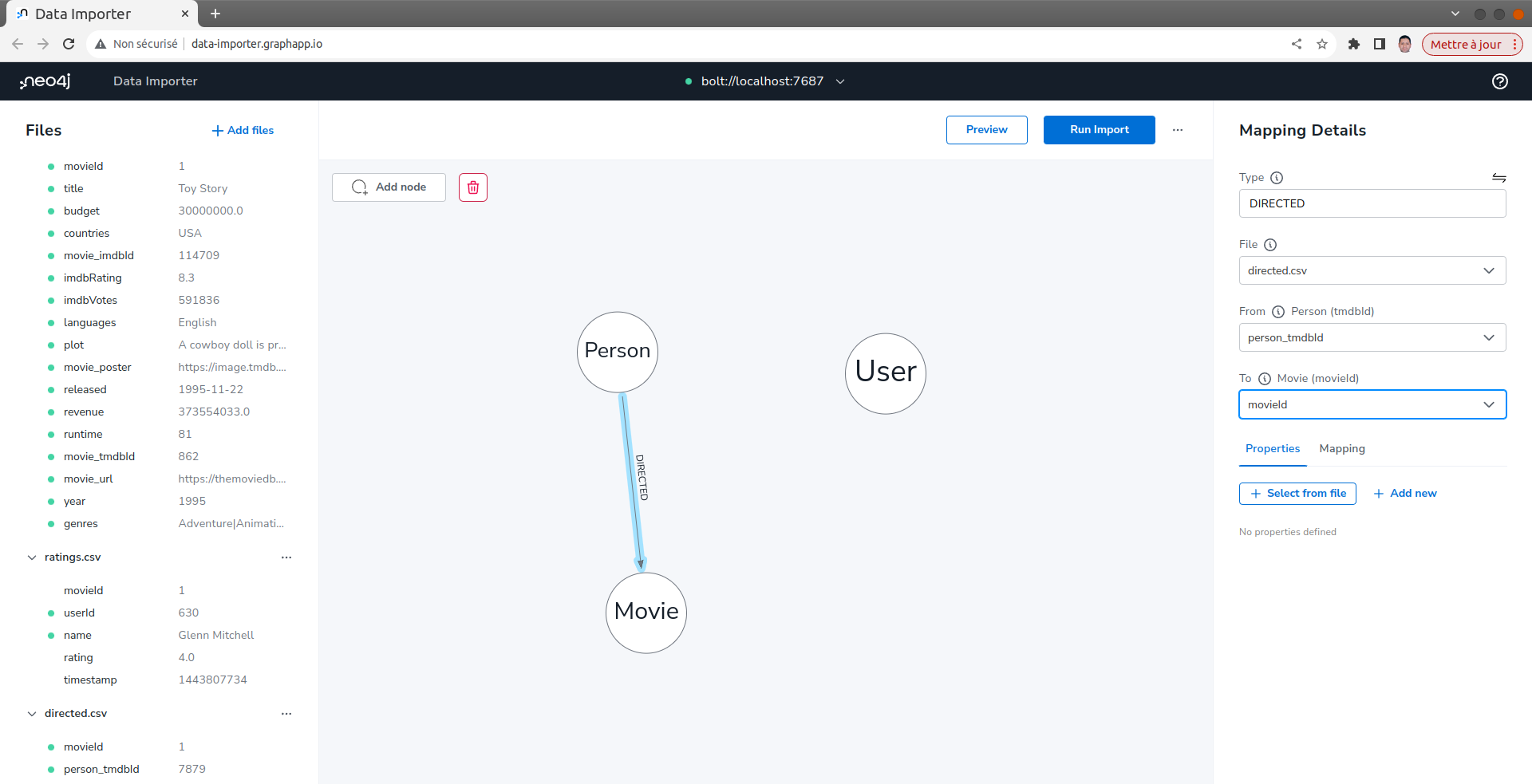
 définisser le mapping des relations DIRECTED
définisser le mapping des relations DIRECTED
- Dans le volet Modèle de graphique, faites glisser le bord du nœud Person sur le nœud Movie. Ceci définira une relation entre ces nœuds dans le graphique.
- Dans le volet Détails du mapping, à droite :
- Entrer DIRECTED pour le type.
- Sélectionner le fichier directed.csv.
- Dans la section From Sélectionner person_tmdbId comme ID de Person.
- Dans la section To Sélectionner movieId comme identifiant de Movie.
 définir le mapping des relations ACTED_IN
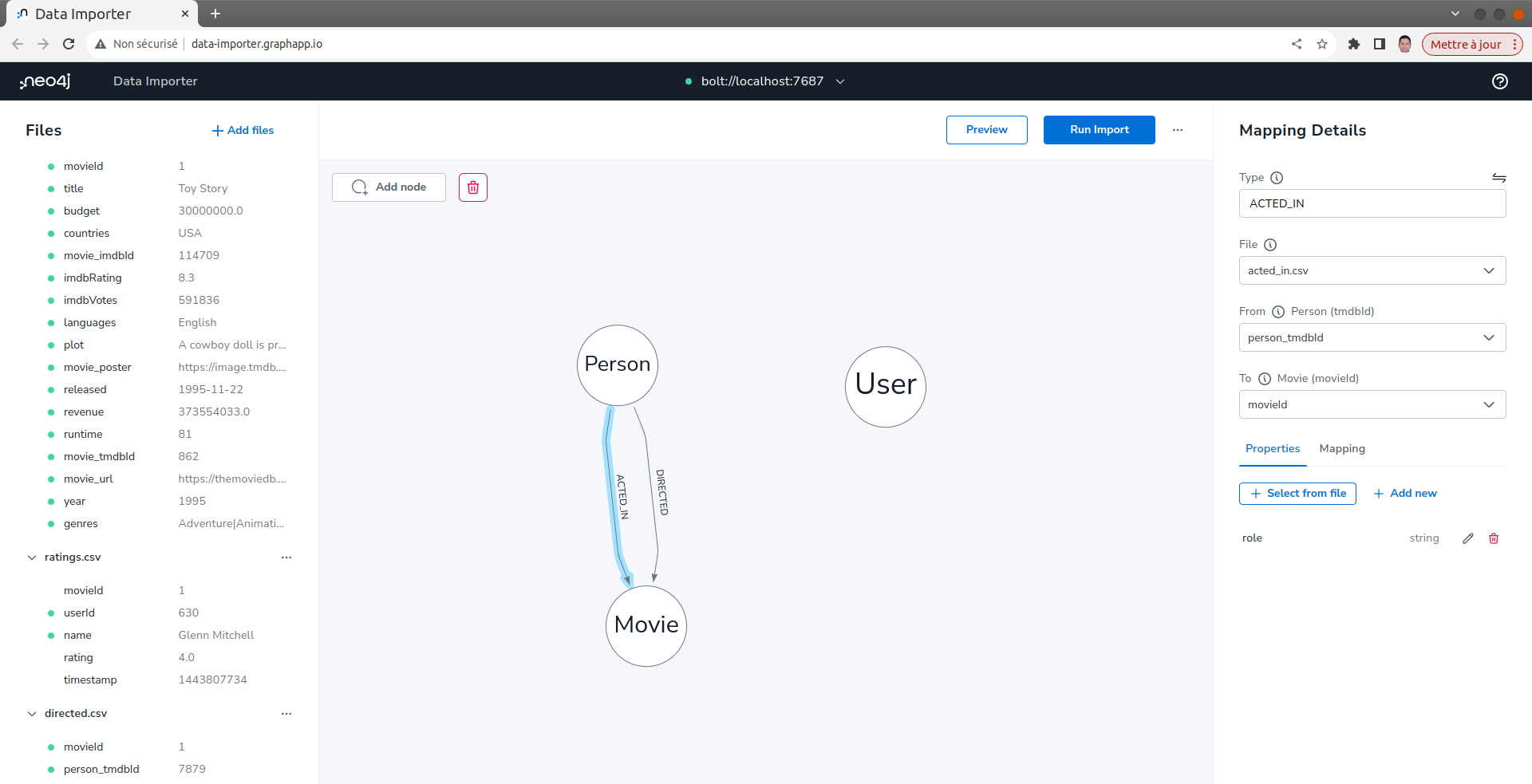
définir le mapping des relations ACTED_IN
- Répéter les opérations de l'étape précédente en utilisant le fichier acted_in.csv.
- Dans la section From Sélectionner person_tmdbId comme ID de Person. et dans From movieId comme ID de Movie.
- Dans la section Properties, sélectionner la propriété role.
 Définir le mapping des relations RATED
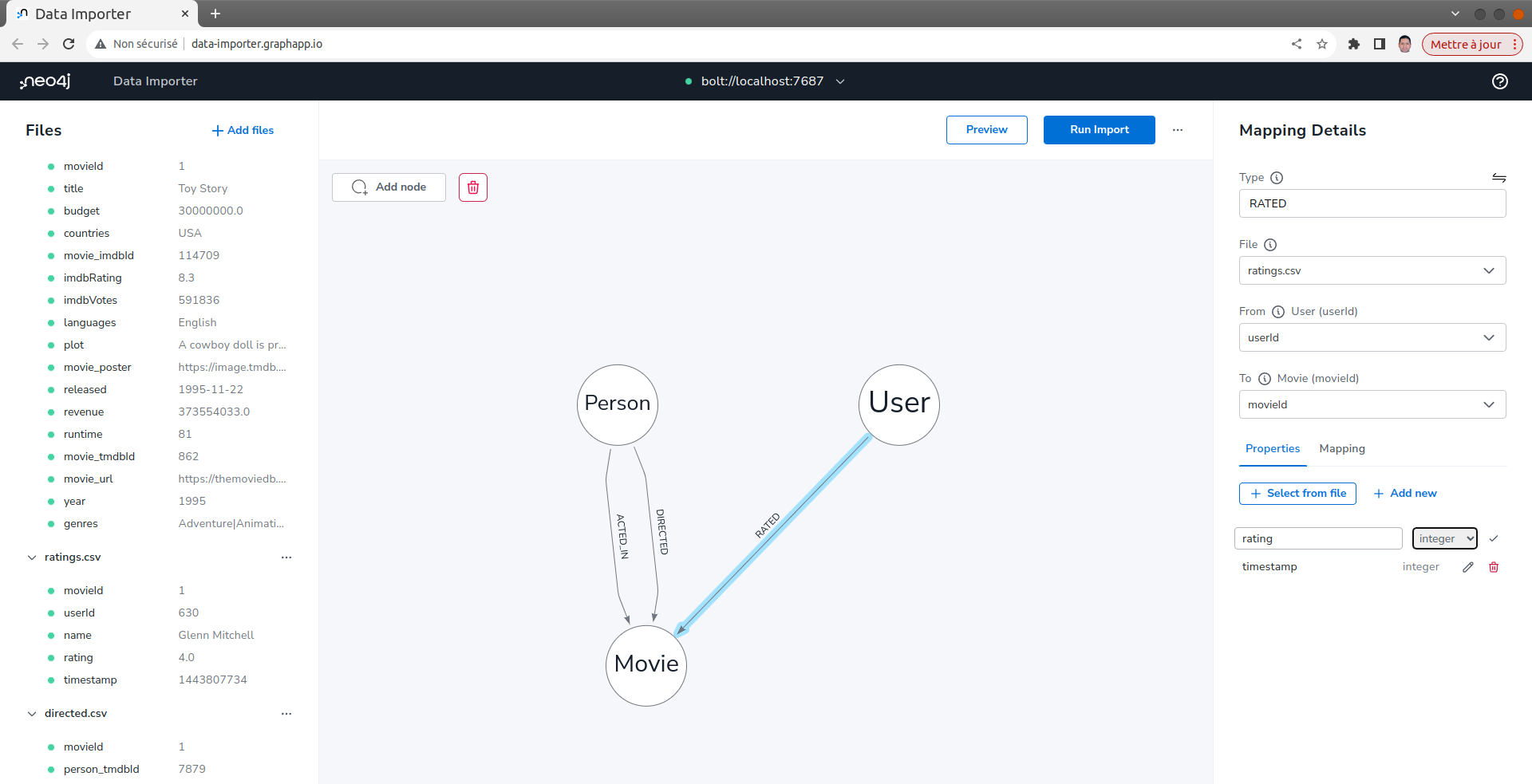
Définir le mapping des relations RATED
Noter que ce mapping réutilisera le même fichier que vous avez utilisé pour définir les noeuds User ratings.csv.
Dans le volet Détails du mapping, à droite : 1. Entrer RATED pour le type. 1. Sélectionner le fichier ratings.csv. 1. Dans la section From sélectionner userId comme ID de User. 1. Sélectionner movieId comme identifiant de Movie dans la section To. 1. Dans la section Propriétés, sélectionner la propriété rating et timestamp. 1. Madifer le type de rating integer
 Enregistrer vos mappings
Enregistrer vos mappings
Au cas où quelque chose se passerait mal pendant l'importation, nous vous recommandons de sauvegarder ce que vous avez mappé.
- Cliquer sur le bouton ... à droite du bouton
Run Import. - Sélectionner Télécharger le modèle. Le fichier portant le nom neo4j_importer_model_yyyy-mm-dd.json sera téléchargé sur votre système.
Importer les données CSV
Cliquer sur le bouton Run Import.
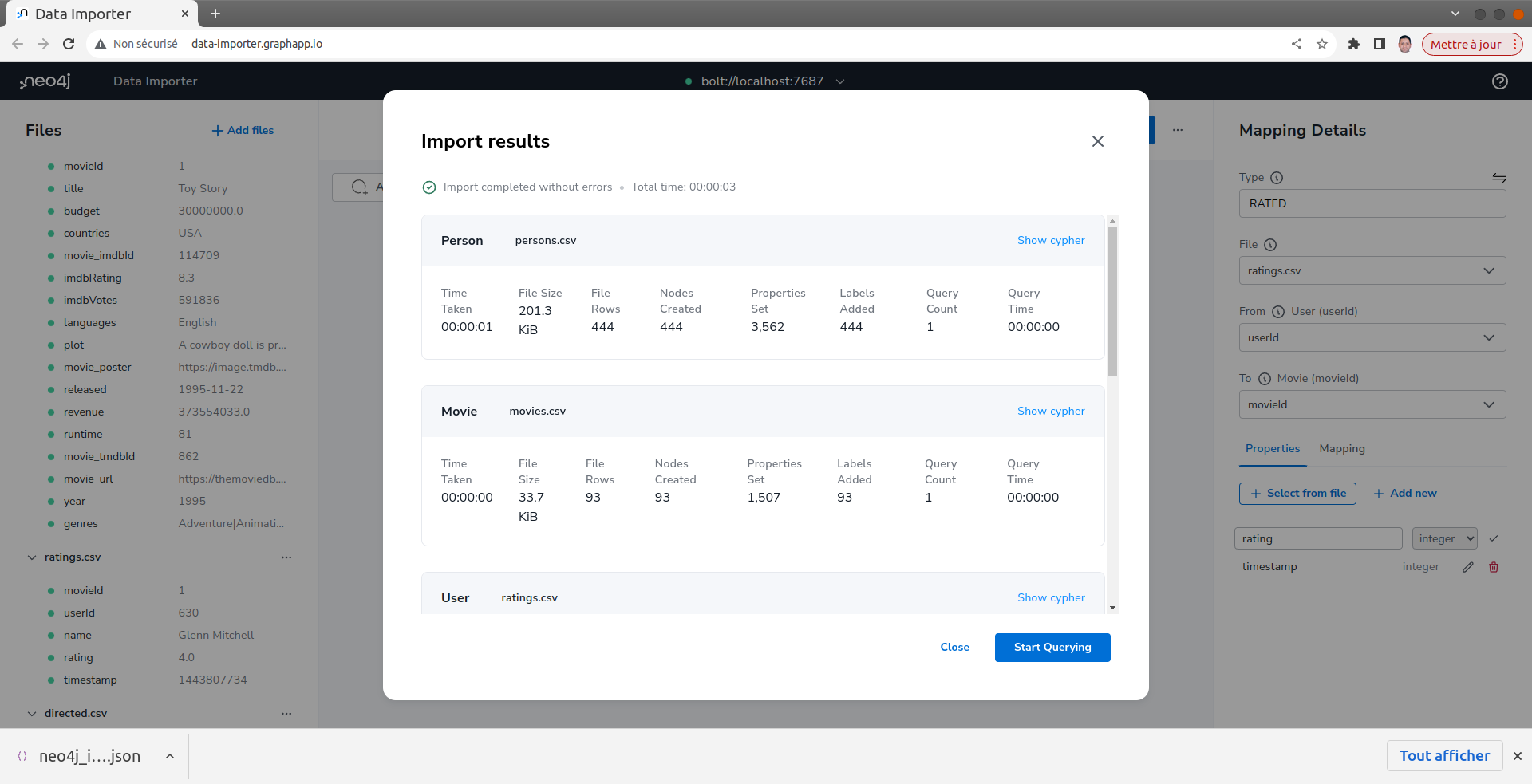
Vérifier les données importées
MATCH (n) RETURN count(n)
Doit retourner 1097 noeuds.
MATCH ()-[r]->() RETURN count(r)
Refactoring post importation de données¶
Après avoir utilisé Data Importer pour importer les données, vous allez utiliser Cypher pour remanier les données importées. Le remaniement de ce modèle de données impliquera :
- Transformer les types de données de chaîne de caractères en liste de chaînes de caractères à valeurs multiples.
MATCH (p:Person) SET p.born = CASE p.born WHEN "" THEN null ELSE date(p.born) END WITH p SET p.died = CASE p.died WHEN "" THEN null ELSE date(p.died) END MATCH (m:Movie) SET m.countries = split(coalesce(m.countries,""), "|"), m.languages = split(coalesce(m.languages,""), "|"), m.genres = split(coalesce(m.genres,""), "|") - Ajouter des Label Actor et Director aux nœuds Person.
MATCH (p:Person)-[:ACTED_IN]->() WITH DISTINCT p SET p:Actor MATCH (p:Person)-[:DIRECTED]->() WITH DISTINCT p SET p:Director - Ajouter plus de contraintes selon le modèle de données du graphe.
CREATE CONSTRAINT Genre_name IF NOT EXISTS FOR (x:Genre) REQUIRE x.name IS UNIQUE - Créer des noeuds Genre à partir des données des noeuds Movie.
MATCH (m:Movie) UNWIND m.genres AS genre WITH m, genre MERGE (g:Genre {name:genre}) MERGE (m)-[:IN_GENRE]->(g) MATCH (m:Movie) SET m.genres = null
Importer les données avec Cypher¶
Supprimer tous les noeuds et relations
MATCH (u:User) DETACH DELETE u;
MATCH (p:Person) DETACH DELETE p;
MATCH (m:Movie) DETACH DELETE m;
MATCH (n) DETACH DELETE n
Ajouter les contraintes après vérification
Vérifier avec :
SHOW CONSTRAINTS
4 contraintes Unique doivent être présentes :
- Person.tmdbId
- Movie.movieId
- User.userId
- Genre.name
Sinon ajouter ces contraintes. Par exemple, pour Genre.name :
CREATE CONSTRAINT Genre_name IF NOT EXISTS
FOR (x:Genre)
REQUIRE x.name IS UNIQUE n
Importer Movie et Genre
:auto USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'https://data.neo4j.com/importing/2-movieData.csv'
AS row
//process only Movie rows
WITH row WHERE row.Entity = "Movie"
MERGE (m:Movie {movieId: toInteger(row.movieId)})
ON CREATE SET
m.tmdbId = toInteger(row.tmdbId),
m.imdbId = toInteger(row.imdbId),
m.imdbRating = toFloat(row.imdbRating),
m.released = datetime(row.released),
m.title = row.title,
m.year = toInteger(row.year),
m.poster = row.poster,
m.runtime = toInteger(row.runtime),
m.countries = split(coalesce(row.countries,""), "|"),
m.imdbVotes = toInteger(row.imdbVotes),
m.revenue = toInteger(row.revenue),
m.plot = row.plot,
m.url = row.url,
m.budget = toInteger(row.budget),
m.languages = split(coalesce(row.languages,""), "|")
WITH m,split(coalesce(row.genres,""), "|") AS genres
UNWIND genres AS genre
WITH m, genre
MERGE (g:Genre {name:genre})
MERGE (m)-[:IN_GENRE]->(g)
Importer les données de Person
:auto USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'https://data.neo4j.com/importing/2-movieData.csv'
AS row
WITH row WHERE row.Entity = "Person"
MERGE (p:Person {tmdbId: toInteger(row.tmdbId)})
ON CREATE SET
p.imdbId = toInteger(row.imdbId),
p.bornIn = row.bornIn,
p.name = row.name,
p.bio = row.bio,
p.poster = row.poster,
p.url = row.url,
p.born = CASE row.born WHEN "" THEN null ELSE date(row.born) END,
p.died = CASE row.died WHEN "" THEN null ELSE date(row.died) END
Ajout des relations ACTED_IN
:auto USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'https://data.neo4j.com/importing/2-movieData.csv'
AS row
WITH row WHERE row.Entity = "Join" AND row.Work = "Acting"
MATCH (p:Person {tmdbId: toInteger(row.tmdbId)})
MATCH (m:Movie {movieId: toInteger(row.movieId)})
MERGE (p)-[r:ACTED_IN]->(m)
ON CREATE
SET r.role = row.role
SET p:Actor
:auto USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'https://data.neo4j.com/importing/2-movieData.csv'
AS row
WITH row WHERE row.Entity = "Join" AND row.Work = "Directing"
MATCH (p:Person {tmdbId: toInteger(row.tmdbId)})
MATCH (m:Movie {movieId: toInteger(row.movieId)})
MERGE (p)-[r:DIRECTED]->(m)
ON CREATE
SET r.role = row.role
SET p:Director
:auto USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'https://data.neo4j.com/importing/2-ratingData.csv'
AS row
MATCH (m:Movie {movieId: toInteger(row.movieId)})
MERGE (u:User {userId: toInteger(row.userId)})
ON CREATE SET u.name = row.name
MERGE (u)-[r:RATED]->(m)
ON CREATE SET r.rating = toInteger(row.rating),
r.timestamp = toInteger(row.timestamp)
Le code complet :
// clear the graph
MATCH (u:User) DETACH DELETE u;
MATCH (p:Person) DETACH DELETE p;
MATCH (m:Movie) DETACH DELETE m;
MATCH (n) DETACH DELETE n;
// make sure all constraints exist
CREATE CONSTRAINT Genre_name IF NOT EXISTS
FOR (x:Genre)
REQUIRE x.name IS UNIQUE;
CREATE CONSTRAINT Movie_movieId IF NOT EXISTS FOR (x:Movie) REQUIRE x.movieId IS UNIQUE;
CREATE CONSTRAINT Person_tmdbId IF NOT EXISTS FOR (x:Person) REQUIRE x.tmdbId IS UNIQUE;
CREATE CONSTRAINT User_userId IF NOT EXISTS FOR (x:User) REQUIRE x.userId IS UNIQUE;
// import the Movie data
:auto USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'https://data.neo4j.com/importing/2-movieData.csv'
AS row
//process only Movie rows
WITH row WHERE row.Entity = "Movie"
MERGE (m:Movie {movieId: row.movieId})
ON CREATE SET
m.tmdbId = row.tmdbId,
m.imdbId = row.imdbId,
m.imdbRating = toFloat(row.imdbRating),
m.released = row.released,
m.title = row.title,
m.year = toInteger(row.year),
m.poster = row.poster,
m.runtime = toInteger(row.runtime),
m.countries = split(coalesce(row.countries,""), "|"),
m.imdbVotes = toInteger(row.imdbVotes),
m.revenue = toInteger(row.revenue),
m.plot = row.plot,
m.url = row.url,
m.budget = toInteger(row.budget),
m.languages = split(coalesce(row.languages,""), "|")
WITH m,split(coalesce(row.genres,""), "|") AS genres
UNWIND genres AS genre
WITH m, genre
MERGE (g:Genre {name:genre})
MERGE (m)-[:IN_GENRE]->(g);
// import the Person data
:auto USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'https://data.neo4j.com/importing/2-movieData.csv'
AS row
WITH row WHERE row.Entity = "Person"
MERGE (p:Person {tmdbId: row.tmdbId})
ON CREATE SET
p.imdbId = row.imdbId,
p.bornIn = row.bornIn,
p.name = row.name,
p.bio = row.bio,
p.poster = row.poster,
p.url = row.url,
p.born = CASE row.born WHEN "" THEN null ELSE date(row.born) END,
p.died = CASE row.died WHEN "" THEN null ELSE date(row.died) END;
// set ACTED_IN relationships and Actor labels
:auto USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'https://data.neo4j.com/importing/2-movieData.csv'
AS row
WITH row WHERE row.Entity = "Join" AND row.Work = "Acting"
MATCH (p:Person {tmdbId: row.tmdbId})
MATCH (m:Movie {movieId: row.movieId})
MERGE (p)-[r:ACTED_IN]->(m)
ON CREATE
SET r.role = row.role
SET p:Actor;
// set DIRECTED relationships and Director labels
:auto USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'https://data.neo4j.com/importing/2-movieData.csv'
AS row
WITH row WHERE row.Entity = "Join" AND row.Work = "Directing"
MATCH (p:Person {tmdbId: row.tmdbId})
MATCH (m:Movie {movieId: row.movieId})
MERGE (p)-[r:DIRECTED]->(m)
ON CREATE
SET r.role = row.role
SET p:Director;
// import the User data
:auto USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'https://data.neo4j.com/importing/2-ratingData.csv'
AS row
MATCH (m:Movie {movieId: row.movieId})
MERGE (u:User {userId: row.userId})
ON CREATE SET u.name = row.name
MERGE (u)-[r:RATED]->(m)
ON CREATE SET r.rating = toInteger(row.rating),
r.timestamp = toInteger(row.timestamp)
Dossier import
Pour importer des fichiers CSV sur la machine locale, il faut les placer dans le dossier import sous le dossier d'installation de Neo4j.
Pour le container docker ce dossier est sous le chemin /var/lib/neo4j/import.
docker cp movieData neo4j:/var/lib/neo4j/import
movieData est un dossier contenant les fichiers CSV. Exercice  ¶
¶


 Données sur les restaurants et leurs inspections
Données sur les restaurants et leurs inspections
- Télécharger l'archive restaurants.zip
- Décompresser le contenu
- Examiner le contenu des fichiers csv (voir ci-dessous)
Il s'agit de données concernant des restaurant de New York et les résultats des inspections réalisées à ces derniers. Ces données sont respectivement dans les fichiers restaurants.csv et restaurants_inspecteions.csv.
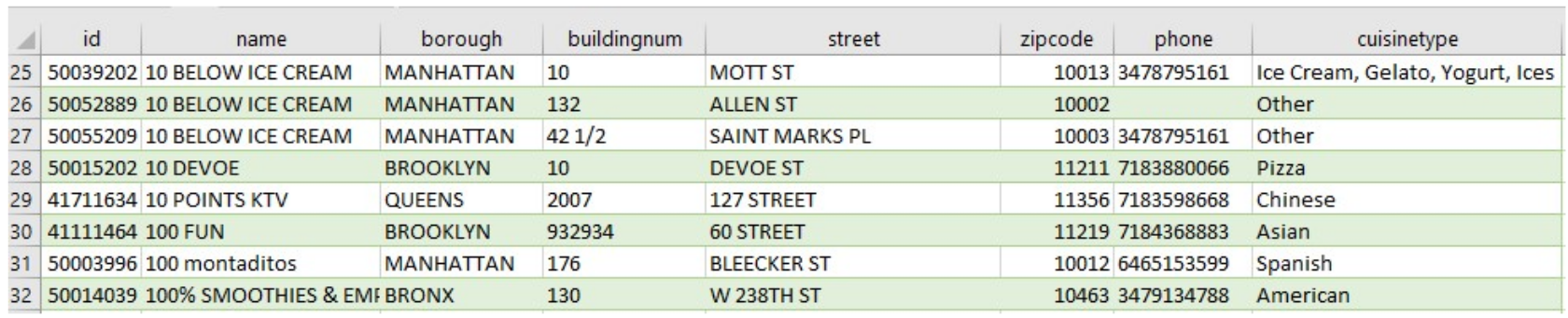

 Travail à faire
Travail à faire
 Importer les données sur Neo4j en créant le graphe de données (à exporter sous le format PNG) en considérant les requêtes suivantes :
Importer les données sur Neo4j en créant le graphe de données (à exporter sous le format PNG) en considérant les requêtes suivantes :
- Chercher les restaurants par spécialité (cuisinetype).
- Chercher les restaurants par Quartier (borough).
- Chercher les restaurants par code de violation.
 Donner les requêtes Cypher pour trouver :
Donner les requêtes Cypher pour trouver :
- Les restaurants de spécialité chinoise dans le quartier du QUEENS.
- Le restaurant ayant commis le plus grand nombre de violations.
- Les restaurants du BRONX ayant des violations de code 04L.